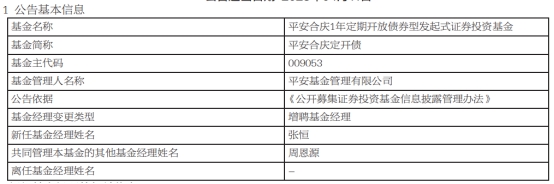
2023-04-03 09:15:27 发布人:hao333 阅读( 1890)
从临近中国的兔年开始,生成式AI(又称AIGC)的发展可谓“兔”飞猛进。
前言
从临近中国的兔年开始,生成式AI(又称AIGC)的发展可谓兔飞猛进。几乎每周都有许多新的消息和成果发布,更低的门槛和更好的效果不断冲击大众认知,让越来越多的人认知到生成式AI已经成为推进下一轮技术革新的重要动力。同时,也有越来越多的人开始思考一些问题,比如:为什么最好的生成效果不在中国?中国的生成式AI离国外有多远?要做出最好的生成式AI,除了模型,我们还需要建设哪些东西?
网易伏羲作为国内首个专注数字文娱领域的人工智能研究机构,从17年成立之初开始关注生成式AI的发展和落地可能,这些问题在过去的几年内不断在团队内部被提及、讨论,并驱动一系列工作的开展和推进。本文将介绍网易伏羲对这些问题的思考,以及当前的一些进展。
自然语言与生成式AI
这一轮生成式AI的爆发,需要从自然语言处理技术的突破说起,17年谷歌提出Transformer架构,使得计算机可以更加高效地进行文本内容知识的学习,从而推动BERT、GPT等一些列大规模文本模型的诞生,从理解和生成的维度都获得了巨大突破。而自然语言处理这门连接人类和计算机交流的基础学科,也成为驱动包括文本、图像、音频、视频、三维模型等各个维度生成式AI爆发的核心基座。一方面人们从海量的互联网数据当中整理可以用于生成式AI训练的数据,另外一方面通过自然语言来对齐各个模态的信息,使得这些知识可以互通。这也可以很好的解释为什么英文生态的公司和机构在这一轮技术热潮中更容易占据先机 -- 当前规模最大、内容最丰富、质量最高的机器学习语料是由英文构成的。
例如文本下游微调数据,英文领域有像T0-SF,Muffin等大量优质的数据集,图文领域也有像LAION-2B,MSCOCO等开源数据集。相比于国内,中文领域虽然这两年也有多个相关数据集的建设,如200G悟道文本预训练数据集,悟空1亿图文对数据集等,但是无论从数量还是质量上来比,与海外的数据还是存在着一定的差距。
除此之外,英文生态本身也具备非常明确的先天优势,其包含了大量其他语种不具备的优质的内容。比如说全球最顶尖的学术论文、编程代码、多个行业领域的规范标准。这些构成了英文的独天得天独厚的优势,也使得基于英文生态的研究方案可以更好的去推动和落地。
如何走出数据困境
面对这样的数据困境,国内的研究者和机构又采取了哪些办法?归结来看大概有4种策略:
1、直接用开源模型,走API翻译
这可能是最直接的方案,尤其在图文生成领域,去年stable diffusion模型开源之后国内有不少创业公司尝试直接基于该模型进行适配训练和推理生成,同时利用 API的翻译接口将中文的输入转化成英文实现对中文用户的支持。这条路线的好处是可以快速地将最新的英文生态的工作应用到国内。缺点也非常明显,一方面是中文翻译可能引起语义的缺失,很多英文这个领域当中常用的说法在中文当中是没有办法很好的表达的,比如说中国的许多成语以及谚语:

相关阅读
RelatedReading猜你喜欢
Guessyoulike