火山引擎DataLeap:五个关键技术,帮助企业搭建“数据目录”
2023-06-21 14:44:40 发布人:hao333 阅读( 6248)
企业如何找到数据、了解数据以及使用数据?这离不开数据目录的能力。
企业如何找到数据、了解数据以及使用数据?
这离不开数据目录的能力。数据目录有着类似于“字典”的作用,能够帮助数据生产者和使用者快速定位数据、解释数据、找到数据,并从中提取业务价值。
对以研发人员为代表的数据生产者来说,他们利用数据目录来组织、梳理各类元数据。例如,数据生产者会将元数据以目录等形式编排到一起,方便维护,并通过打业务标签、添加应用场景描述、字段解释等丰富业务相关属性。
对于数据分析师、产品、运营等数据使用者来说,他们通过数据目录来查找和理解数据,例如通过关键字检索,或目录浏览,来查找业务场景数据,并浏览详情介绍、字段描述、产出关系等,进一步理解并利用数据决策。
在字节跳动,也有这么一套被内部广泛使用的数据目录系统。目前,该系统已通过火山引擎DataLeap数据地图平台对外输出。外部用户也可以在DataLeap数据地图平台,收集、组织、访问和补充元数据信息,为自身数据建设和治理提供支持。
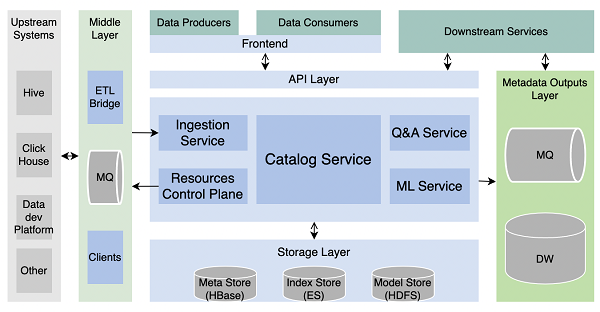
火山引擎DataLeap数据地图平台-数据目录
要构建一套扩展性强、易维护且易用的数据目录系统并非易事。在大数据领域,各类计算和存储系统百花齐放,概念和原理又千差万别,对于元数据的采集、组织、理解、信任等,都带来了很大挑战。
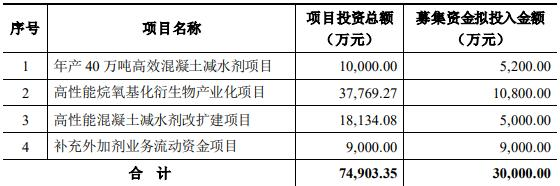
在调研各个开源软件及技术体系基础上,火山引擎DataLeap选择基于Apache Atlas改造,而这套数据目录系统主要依赖五大关键技术:
第一,数据模型统一。一方面,DataLeap通过充分复用各种元数据类型间的相似能力,获得数据模型定制灵活性;另一方面,DataLeap将数据源关联的能力进行收敛到一起,以降低后续的维护成本。
第二,数据接入标准化。当用户接入新的元数据时,只需要重新编写Source和Diff Operator,而其他组件可直接复用,以标准化的connector节省接入和运维成本。
第三,搜索优化。在数据目录中,搜索是用户最广泛使用的功能,也是用户找数主要的手段。搜索优化可分为离线部分和在线部分。离线部分负责汇集各类与搜索相关的数据,完成数据清洗或者模型训练,再根据不同的用途,写入不同的存储,供给在线搜索模块使用。在线部分则分为搜索理解、召回、精排三个主要阶段,步骤和概念与通用搜索引擎对齐。
第四,血缘能力。完备的血缘能力,既可以帮助数据生产者梳理、组织元数据,也可以帮助数据消费者找数、理解数据上下文。火山引擎DataLeap在设计上充分考虑血缘链路的多样性和复杂性,并在血缘质量上,通过定义有效的血缘准确率、覆盖率和时效性,确保血缘信息准确、全面和实时性。
第五,存储层优化。当业务中有越来越多的元数据接入数据目录,图存储中的点和边将分别到达百万和千万量级,造成读写性能出现问题。在读优化和写优化层面,火山引擎DataLeap分别通过开启MutilPreFetch 能力、去除Guid全局唯一性检查,最终实现小表性能小于100ms、中表性能2~5s、大表性能0.5~1min。
据介绍,火山引擎DataLeap能帮助企业快速完成数据集成、开发、运维、治理、资产、安全等全套数据中台建设,其中数据目录能力主要涵盖在数据地图平台,该平台通过提供数据检索、元数据详情查看、数据理解等功能,解决找数难、理解数据难的痛点,同时支持数据专题、血缘图谱、数据发现、库表管理等特色功能。
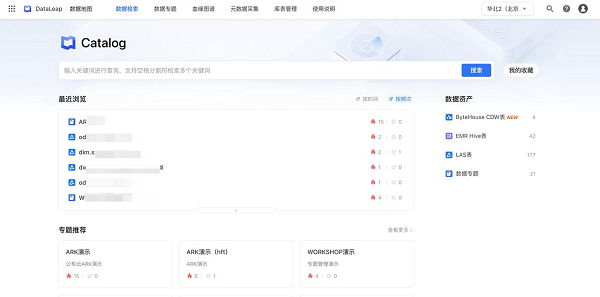
目前,火山引擎DataLeap的数据地图平台已接入全链路核心元数据,包括LAS、MySQL、ByteHouse CE、ByteHouse CDW、TOS、LasFS、EMR hive等,提供可视化的血缘关系展示能力,帮助用户全面的探查了解数据,支持表、字段级别血缘可视化查询,以及按层级、范围筛选展示,为用户提供灵活、易用的数据服务。(作者:于宇灿)
相关阅读
RelatedReading




猜你喜欢
Guessyoulike
“元力觉醒·新浪VR 2022年度行业奖项”公布,积木易搭荣获最佳品牌价值元空间厂商奖与最佳品牌营销案例奖

巴旦木丰收是什么季节(巴旦木的收获季是哪季)

TORVA拓屋:4.0智能洗碗机工厂发挥领航者的力量,引领洗碗机行业发展