2023-08-08 09:48:43 发布人:hao333 阅读( 2927)
起初,ChatGPT爆火出圈是一件令人兴奋的事。
起初,ChatGPT爆火出圈是一件令人兴奋的事。无论是AI行业相关从业者,还是关注科技发展趋势的普通人都能真切感受到这股扑面而来的热浪,仿佛 “每条大街小巷,每个人的嘴里,见面第一句话,就是AIGC”。ChatGPT的横空出世,不仅带来了AI的“iPhone”时刻,还使处在下行周期的全球半导体市场迎来转折点。据毕马威报告,ChatGPT等人工智能平台的出现,有望促进产生新的应用程序和平台,创造为行业和未来几年带来数千亿美元收入的细分市场。
同时,这个 “超费电”、“超费钱”又“超聪明”的“三超大户”也给社会增添了许多焦虑情绪。前微软全球副总裁、百度COO、奇迹创坛创始人陆奇表示:“从现在开始,不论工作还是创业,请确保自己跟AI有关”, “AIGC不是什么当下风口,风口意味着投机主义,未免太低估AI对世界发展的影响。” 时代正在发生变化,你我皆应有所准备。
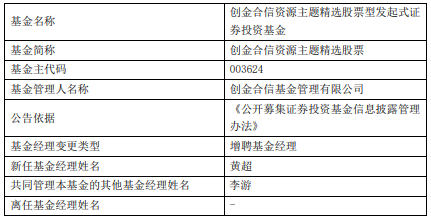
AI 2.0时代到来,108模型“好汉”各显身手,谁会成为MaaS“四小龙“
也许再过几年回头看,2023会是人工智能发展史上不可忽视的一年。就像《2001太空漫游》里的那块黑色石板,它第一次出现时,猿猴们围着它好奇地打转,最终受到启发,学会了使用工具,进化成了人类;而当它再一次出现时,又引导人类向着更高维度前进,穿过万千星海,直到成为宇宙本身。
2012年,Alexnet一鸣惊人,一举摘得imagenet图像识别类的冠军,将图像识别的正确率提升到85%。以CNN为核心的人工智能技术,机器开始在计算机视觉(CV)等领域超越人类,开启了AI 1.0时代。
十年后,2022年底,ChatGPT横空出世,建立在海量数据训练的基础上,克服了单领域、多模型的限制,也打破了人类对于传统NLP人机交互中“人工智障”的偏见,驱动各行各业的AI应用进入2.0时代。我们很幸运,可以在短短十年间,见证人工智能跨时代的两个突破节点。
从今年3月以来,AIGC与大模型产品几乎是爆发式地推出,呈现出百花齐放之势,AI领域的模型更新已经是按周来迭代。就在不久前,meta将其LLama2的模型开放商用。模型越来越大,应用越来越多。当前国产大模型已经达到108个,正如水浒108好汉,人工智能领域自媒体走向未来甚至以“谁是36天罡?谁是72地煞?”为题评选出了百模争霸排行榜。
在刚刚闭幕的2023年世界半导体大会(WSCE)上,AI大算力芯片公司亿铸科技副总裁李明发表了题为《以存算一体架构创新,迎AI 2.0时代》的演讲,他预测,最早在明年,国内也可能初步形成MaaS(Model as a Servic, 模型即服务)四小龙的竞争格局。就像在2014-2017年,基于CNN AI网络,国内也曾形成了CV(机器视觉)应用四小龙的竞争格局,继而引领了AI视觉领域数年的蓬勃发展。

算力、能源双重挑战,计算架构创新是“解药”
生成式AI惊艳全世界的背后离不开超大算力的加持。最近,IDC、浪潮信息和清华大学全球产业研究院联合发布了《2022-2023全球计算力指数评估报告》。报告指出,“计算力与经济增长紧密相关,计算力指数平均每提高1个点,数字经济和GDP将分别增长3.3‰和1.8‰”。首次揭示了算力即生产力的事实。
眼下,transformer的划时代革新,不但会促成AI向通用人工智能AGI领域发展,还会引领第二次AI应用场景的爆发。而在此过程中,势必会产生上千亿美金的算力需求。
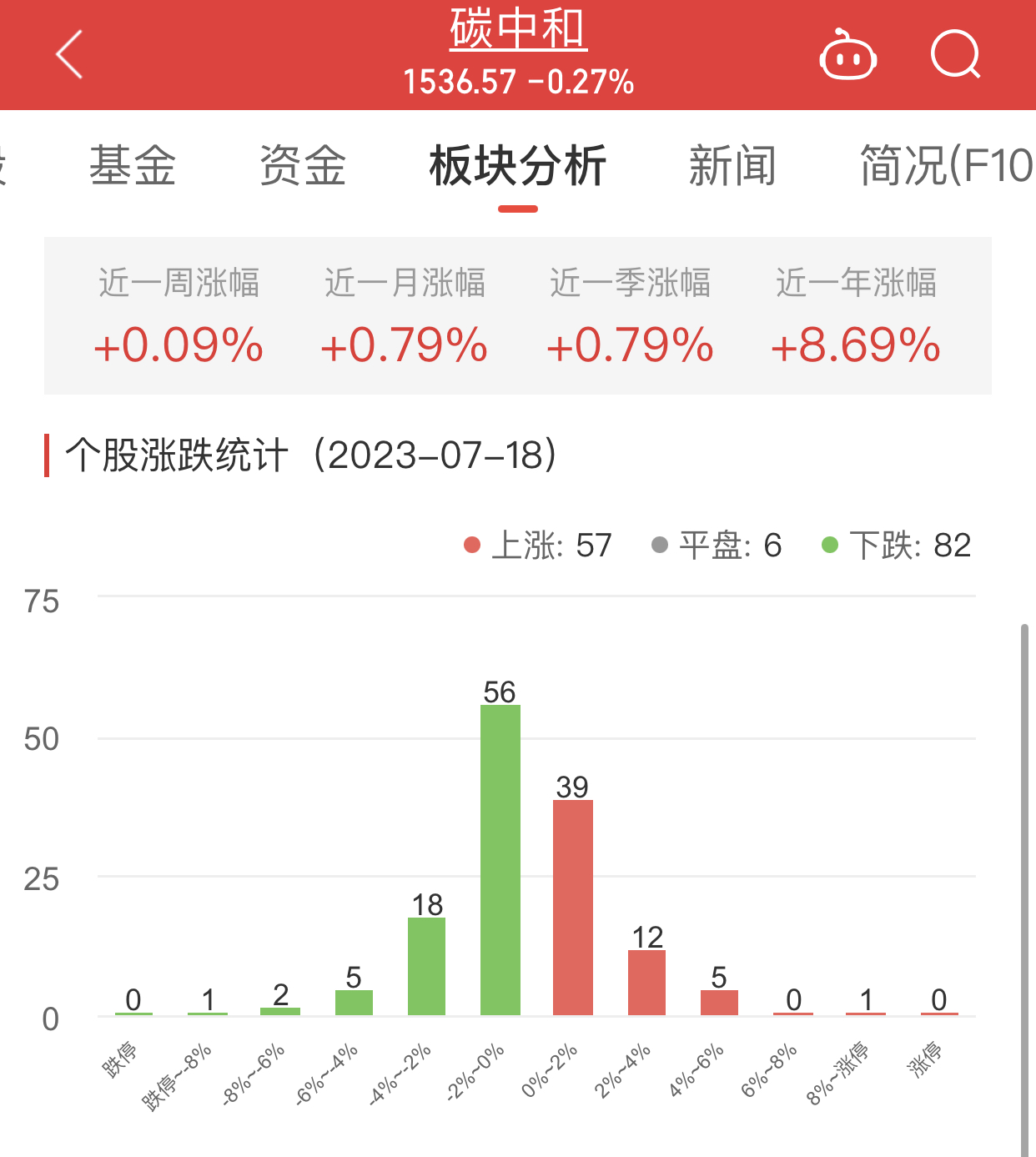
据中国信通院等机构的调研数据,ChatGPT的单日运营算力消耗占整个2021年中国智能算力总规模的3%。而这只是Open AI的一个模型而已,如果中国的百大模型持续蓬勃发展,对国内的智能算力要求将达到惊人的天文数字。
“假设目前的ChatGPT3平均每张H100每秒可以生成6个tokens(FP16,参数350GB),在不考虑级联或者模型稀疏化的前提下,假设每人每天提5个问题,每个问题会和GPT交互5次,每次消耗30个token,那么每人每天会消耗750个token,如果每天有1亿人在线使用查询,就需要约15万颗H100芯片,仅仅H100卡的硬件成本会达到50亿美金以上。如果计算系统成本的话,100亿美金也很难覆盖。” 李明补充道。
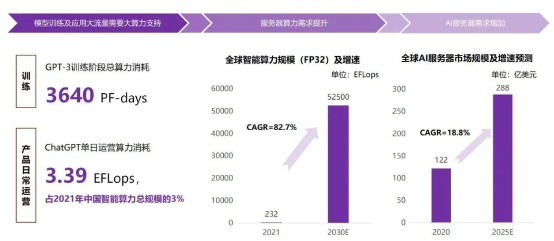
算力需求不断提升带来的挑战除了贵,还有费电。在今年国际集成电路设计领域最高级别会议 ISSCC上,AMD全球CEO LisaSu表示,目前实现Exascale(百亿亿次计算)的超级计算机功耗已经到达2100万瓦。而根据Green500的预计,到2035年,实现Zettascale(十万亿亿次计算)级别的一台超级计算机的功率会达到500 MW,相当于半个核电站的发电功率,到那时,世界再多的核电站也难以支撑如此大电力的消耗。而2035年离我们也并不遥远。
回到ChatGPT3的场景假设,亿铸科技认为,未来随着大模型的普级,如果有1亿人同时在线,在线提问率提升到30%,每个promt占30个token的话,就差不多需要1700万颗H100芯片来提供其推理算力,每颗H100的功耗在750W左右,该模型每天假设只运行10个小时,这些H100芯片所在的数据中心一年的耗电量将超过三峡大坝一年的发电量。
从技术环境来看,未来数据量会越来越大、模型算法越来越复杂,算力要求越来越高,而支撑底层算力的摩尔定律却几近终结。巨大的剪刀差落在AI大算力芯片企业产业链的肩 上,从而带来了巨大的压力:比如有效算力的增长率、软件的编译、数据的带宽、存储的成本、能效比、生产工艺等等。
以AI云端推理卡为例,近年来由于工艺制程“卷不动”等种种原因,成本、功耗、算力难以兼顾。目前国内主流AI芯片厂商、初创企业纷纷谋求计算架构创新,试图找出兼顾性能、规模、能源利用率的方案,突破算力天花板。
清华大学集成电路学院副院长尹首一教授认为,在当前国际产业环境下,需要重新审视芯片算力公式,在可获取的低世代成熟工艺下去寻找持续提升算力的新途径,其中包括在芯片面积上探索先进集成技术和先进封装技术发展的可能性,以及在算力方面更加聚焦新型计算架构。

存算一体乘风起,扶摇直上解困局
存算一体化概念的提出最早可以追溯到上个世纪七十年代,斯坦福研究所的Kautz教授团队于1969年提出了存算一体化的概念,期望直接利用内存做一些简单的计算,减少数据在处理器与存储器之间的搬移。
2016年的ISCA上,存算一体的相关论文开始出现。到了Micro 2017,英伟达、英特尔、微软、三星、加州大学圣塔芭芭拉分校等都推出了他们的存算一体系统原型。世界上第一颗存算一体芯片在ISSCC 2018年首次出现,今年已经是存算一体芯片工程落地走过的第7个年头了。
近年来关于存算一体相关的报道、研究源源不断涌现。学界,ISSCC上存算/近存相关的文章数量迅速增加:从20年的6篇上涨到23年的19篇;其中数字存内计算,从21年被首次提出后,22年迅速增加到4篇。产界,巨头纷纷布局存算一体,国内陆陆续续也有近十几家初创公司押注该架构,这“扶摇直上”的架势,不仅仅是因为存算一体是天生为AI大模型计算而生的一种架构,乘了大模型的“东风”,更是因为该架构解决了长久以来造成算力发展困局的根本原因——“存储墙”。
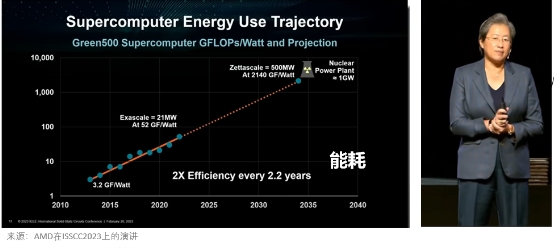
存算一体架构是相对于传统冯·诺伊曼架构下的存算分离而言的。从技术理论的角度来看,要从阿姆达尔定律讲起。阿姆达尔定律是硬件加速设计的基本定律。这个定律包括两个因子,一个是加速器规模α,可以用先进的工艺或者优化设计去提升其工作频率,叠加之后就形成了 “裸算力”;而另一个因子F则是在计算周期里数据访存所占的百分比。
IBM的科学家做过一个研究,在存算分离的冯·诺依曼架构下,F值达到了90%以上,也就是每一次计算,数据搬运访存的时间超过90%,功耗也超过90%。这意味着即使现在用5nm,将来做到0.5nm;现在花1亿做一颗芯片,将来花10亿去做一颗芯片,可以提升的性能空间也只有10%。
那么,如何减小F值呢?近存储计算是一种途径。例如,特斯拉的Dojo D1用近存储,如果能将F值降到0.2、0.3,这意味着即使工艺还是7nm,性能也会提升3-4倍。
存内计算则是更进一步——亿铸科技希望通过存算一体(CIM)把F值降低到0.1以下,如此一来,未来芯片的性能提升将主要取决于工艺的提升和设计的优化。
存算一体超异构开启AI算力芯片换道发展之路
据李明透露,亿铸早就已经根据ReRAM(RRAM)的特性着手使用先进异构封装的方式来实现系统级的芯片优化方案;在今年3月,亿铸科技正式公布了存算一体超异构芯片这一创新理念。它将会以存算一体(CIM)AI加速计算单元为核心,同时将不同的计算单元进行异构集成,以实现更大的AI算力以及更高的能效比,同时提供更为通用的软件生态,使得CIM AI大算力芯片真正满足AI算力增长第二曲线的需求,开启一条AI大算力芯片换道发展之路。
这颗存算一体芯片可实现基于75W功耗达到单芯片1P的算力,相比传统冯·诺依曼架构的AI推理芯片提升10倍左右的能效比,同时还能兼顾软件通用性。
李明表示,通过亿铸“四新一强”的整体优势,也就是存算一体架构创新、ReRAM新型忆阻器的应用创新、全数字化技术路径应用创新、存算一体超异构系统级创新以及极强的专业团队阵容,一定可以成为AI2.0时代破局的一道光。
相关阅读
RelatedReading猜你喜欢
Guessyoulike