2023-09-07 17:36:50 发布人:hao333 阅读( 6364)
作者|蒋浇百川智能又发布大模型了。9月6日,王小川旗下百川智能正式发布开源微调后的Baichuan 2-7B、Baichuan 2-13B、Baichuan 2...

作者|蒋浇
百川智能又发布大模型了。
9月6日,王小川旗下百川智能正式发布开源微调后的Baichuan 2-7B、Baichuan 2-13B、Baichuan 2-13B-Chat与其4bit量化版本,均为免费可商用,这是继6月15日发布首款开源大模型Baichuan7B后的又一次重大技术迭代。
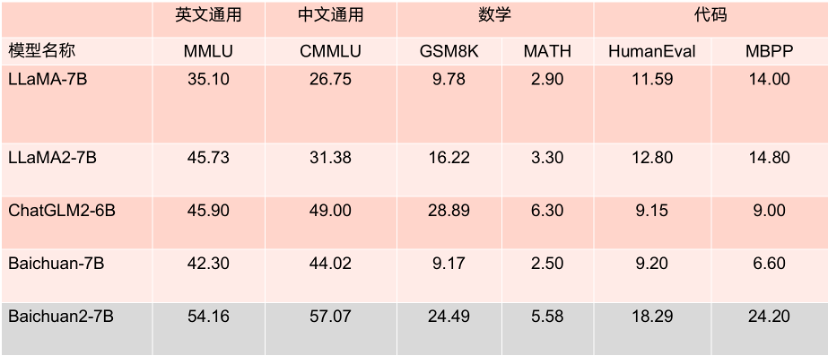
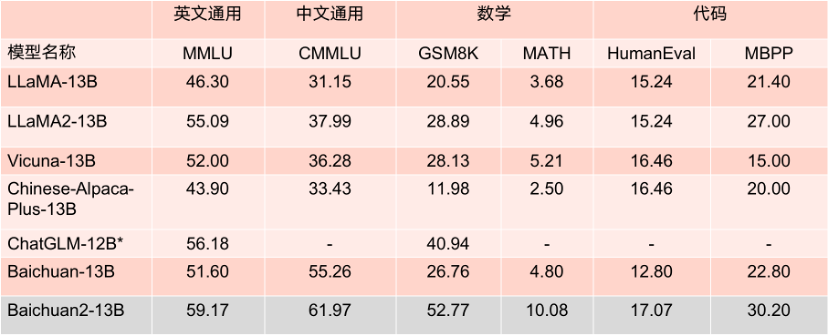
据了解,Baichuan 2-7B-Base 和 Baichuan 2-13B-Base,均基于 2.6万亿高质量多语言数据进行训练。其中Baichuan 2-13B-Base相比上一代13B模型,数学能力提升49%,代码能力提升46%,安全能力提升37%,逻辑推理能力提升25%,语义理解能力提升15%。
王小川称,70亿参数的Baichuan2-7B开源大模型中文水平超越了LLaMA2 130亿参数模;在英文的评测上,Baichuan2-7B开水平与LLaMA2 130亿参数模型持平。
他表示,“随着国内Baichuan2开源大模型的发布,用LLaMA2作为大家一个开源模型的时代已经过去了。”
国内“百模大战”中,各家都在卷参数规模,卷响应速度,卷行业落地。而在国外,AI模型竞争主要聚焦在“生态封闭”和“生态开源”。其中,闭源模型的代表当属目前最强的GPT-4模型,开源最具代表意义的则是Meta的LLaMA2模型。
业内普遍认为,开源大模型对于大量开发者是一个福音,能够降低做大模型应用的门槛。美国斯坦福大学基金会模型研究中心主任Percy Liang 曾指出,像LLaMA2这样强大的开源模型会对OpenAI 构成相当大的威胁。
今年6月,王小川飞往美国硅谷与同行交流大模型技术思路。他认为,美国闭源大模型的头部格局已定,OpenAI、Anthropic、Google已经拿到门票,LLaMA2则统一了美国开源模型市场,而国内大模型格局还未定型,创业公司还有较大的机会。
在8月举办的一次媒体交流会上,王小川谈及大模型技术路线之争时表示,开源与闭源并不矛盾,未来会像苹果和安卓系统一样并行发展。未来可能80%的企业会用到开源模型,因为开源模型小巧,最后靠闭源提供剩下20%的增值服务。 从2B的角度,开源、闭源都需要,百川智能不会只瞄准一个方向。
王小川指出了LLaMA开源模型的隐藏限制因素。他表示,LLaMA 开源模型适用于以英文为主的环境,开发者使用中文场景是拿不到开源协议,Baichuan2开源大模型更适用于中文大模型。
“我们现在可以获得比LLaMA更友好且能力更强的开源模型,能够帮助扶持中国整个生态的发展。除开源模型以外,下一次在闭源方面会有更多的突破,希望在中国的开源闭源里都能给中国的经济社会发展带来我们的贡献。”
当前大部分开源模型在开源过程中只是对外公开自身的模型权重,很少提及训练细节,企业、研究机构、开发者们只能在开源模型的基础上做有限的微调,很难进行深入研究。
王小川表示,百川智能公开了Baichuan2开源大模型训练过程中的全部参数模型,以及不同大小的 tokens、训练切片,使得学术界在进行预训练微调、强化时更容易操作,更容易获得学术经验和成果。他透露,这也是国内首次开放训练过程。
百川智能创立于今年4月10日,旨在打造构建中国最好的大模型底座,并在教育、医疗等领域应用落地。截至目前,百川智能已公布首轮5000万美元融资。
成立不到半年时间,百川智能平均每28天发布一款大模型,已相继发布了Baichuan-7B、Baichuan-13B两款开源免费可商用的中文大模型,以及一款搜索增强大模型Baichuan-53B。
8月31日,百川智能通过《生成式人工智能服务管理暂行办法》备案,旗下大模型可以正式面向公众提供服务。
上一篇:“YVR”正式更名为“玩出梦想”
相关阅读
RelatedReading猜你喜欢
Guessyoulike