2023-09-15 12:12:40 发布人:hao333 阅读( 8180)
2022年9月9日,掘力计划第23期线上技术分享活动以“AIGC的应用和创新”为主题,邀请到 Jina AI 工程师季光辉进行了主题为《多模态大模型为视觉障碍者打造无障碍数字体验》的演讲。
2022年9月9日,掘力计划第23期线上技术分享活动以“AIGC的应用和创新”为主题,邀请到 Jina AI 工程师季光辉进行了主题为《多模态大模型为视觉障碍者打造无障碍数字体验》的演讲。他介绍了多模态人工智能产品 SceneXplain 如何通过算法创新,为残障人士提供平等的数字体验,网站链接:scenex.jinaai.cn/a/NEW。
直播回放地址:https://juejin.cn/live/jpowermeetup23

数字时代的无障碍体验
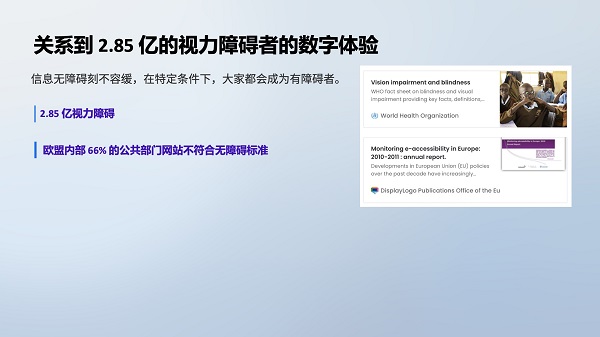
随着移动互联网的兴起,“无障碍”已成为这个时代的重要词汇。它意味着不论性别、年龄或能力如何,每个人都能平等地获得数字产品和服务。对残障人士而言,无障碍体验尤为关键。以视障群体为例,全球约有 2.85 亿视力障碍者,其中包括 3900 万盲人。因此,如何通过科技创新为他们提供更好的数字体验,已成为一个非常迫切的需求。发达国家也开始出台相关法规,要求政府部门网站达到无障碍标准。
然而,就目前而言,无障碍体验还存在诸多不足。以网站为例,欧盟内仅有 34% 的政府网站达标;即便达标的网站,图像描述也往往过于简单或不准确。这主要是由于现有图像描述算法的局限所致。
传统图像描述算法的局限
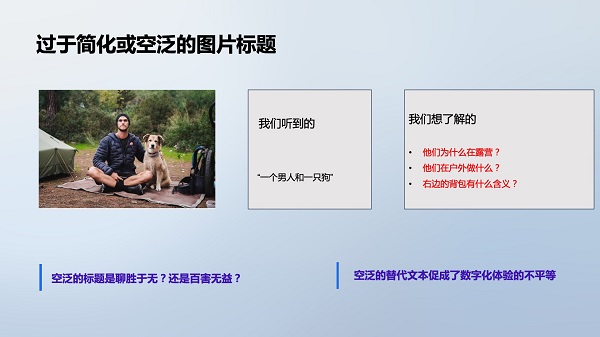
对视障用户而言,网站图片的替代文本是实现无障碍的关键。但手动编写图像描述是一项艰巨的工作,而现有算法生成的描述往往不够丰富和准确。具体问题包括:
●图像细节缺失:算法无法准确表达图像的细节,导致视障用户难以理解图像内容。
●情感表达不足:算法无法捕捉图像所要表达的氛围与情感。
●空间关系理解不足:不同的空间关系会表达不同的意义,但算法难以识别。
●抗干扰能力弱:图像质量下降时,算法的描述能力会大幅降低。
总体来说,现有图像描述算法要么只能生成图像提示词,无法形成流畅的语言描述;要么对复杂图像理解不足,无法生成高质量的描述。
SceneXplain:多模态算法生成高密度图像描述

针对上述问题,Jina AI 研发的 SceneXplain 利用多模态深度学习算法,实现了图像高密度描述的自动生成。该算法专注处理复杂场景图像,通过多语言描述呈现图像细节。其优势包括:
●捕捉图像细节。可准确描述复杂图像的场景元素、空间关系等细节。
●抓取图像情感。可分析作品的语调和氛围,帮助用户理解图像情感。
●生成连贯描述。融合多模态信息,以流畅自然的语言描述图像。
●强大抗干扰。可应对低质量、噪声图像,输出可靠描述。
通过案例分析,SceneXplain 明显优于旧有算法。它可生成上下文丰富、情感细腻的描述,帮助视障用户充分理解图像所传达的信息。

除图像外,SceneXplain 也可自动描述视频内容。它可解析不同语言的视频,识别关键场景,并产出多语言描述,带来更好的视频无障碍体验。
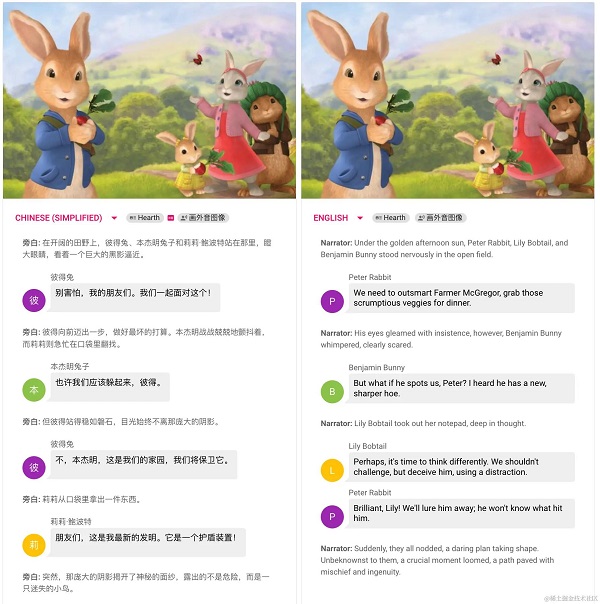
对开发者而言,SceneXplain 提供灵活的 API 接口,支持自定义描述长度、语言等。开发者可以基于该API开发无障碍应用插件,为更多用户提供无障碍服务。
以科技促进无障碍发展
数字时代,我们有责任利用科技力量,为每个人创造公平的数字体验。SceneXplain 正是基于这样的理念诞生的产品。它展示了人工智能算法的进步如何惠及残障群体,为他们带来比文字和图像更丰富的数字体验。让我们一起期待人工智能为弱势群体带来更多惊喜,构建充满温度与阳光的数字社会。
相关阅读
RelatedReading猜你喜欢
Guessyoulike