打破美国AI公司霸榜,上交AI数学开源模型阿贝尔排行榜首
2023-09-21 13:24:49 发布人:hao333 阅读( 9102)
以 ChatGPT 为代表的大模型产品引领了一场新的产业革命,激发了国内外各机构积极投入相关技术研究的热情。在过去几个月的技术竞争中,国产大模型在文本理解和知识...
以 ChatGPT 为代表的大模型产品引领了一场新的产业革命,激发了国内外各机构积极投入相关技术研究的热情。在过去几个月的技术竞争中,国产大模型在文本理解和知识理解任务方面表现出色,堪称一位优秀的 “文科生”。
然而,在复杂数学推理计算、物理建模、科学发现等 “理科” 领域,大模型的研究尚未达到令人满意的水平,与美国顶尖科技公司相比,仍存在很大差距。例如,在数学推理方面的权威评测集 GSM8K 和 MATH 上,美国 AI 公司一直占据前几名,突显了其领先地位。
在这样的背景下,上海交大生成式人工智能研究组 积极攻克难关,研发并开源了数学计算大模型 “阿贝尔”,在多个榜单上取得开源第一!是首个海内外高校团队推出的 SOTA 数学开源大模型。

项目主页:https://GAIR-NLP.github.io/abel
开源模型:https://github.com/GAIR-NLP/abel
“在还未回国前,我和 Meta 非常优秀的科学家合作了一篇叫做 LIMA 的工作,在那篇工作里我们仅使用 1000 个样本就可以训练模型使其在达到接近 GPT4 的水平。但是这种 “少即是多” 的思想并没有在所有的任务场景上都得到了验证,比如数学推理。这也成为当时的遗憾,使得我对如何让大模型学好数学充满了兴趣。”上海交大生成式人工智能研究组负责人同时也是阿贝尔项目的负责人刘鹏飞分享道。“Abel 是为了致敬挪威伟大数学家 尼尔斯・阿贝尔 在代数和分析方面的开创性工作而创建的,代数也是现在模型相对擅长解决的,不过,我们还有很长的路要走。”
01
模型表现
表 1:🔒 代表专有模型,而 🌍 表示开源模型,🎓 表示模型开发由学术大学主导;这里仅考虑不使用任何工具的模型;GAIRMath-Abel 为该团队提出的模型
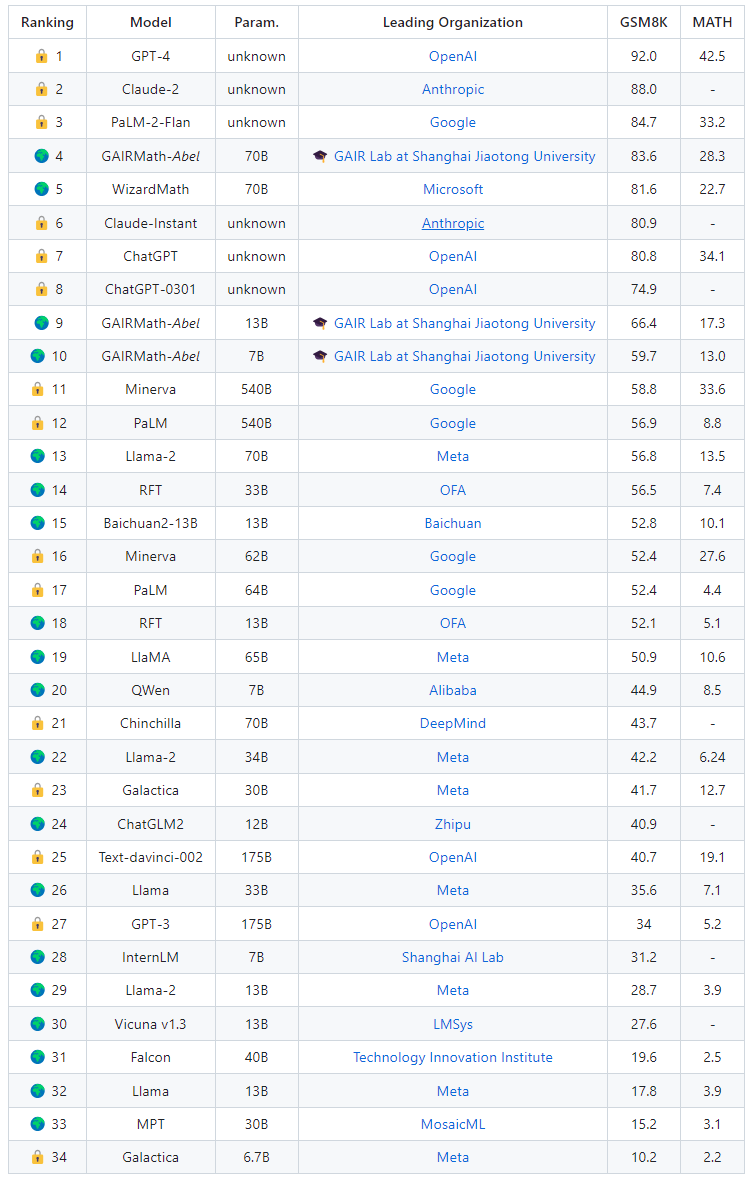
在阿贝尔这个项目里,作者展示了,尽管
没有使用工具
没有使用数学领域的大规模预训练数据
没有使用奖励模型
没有使用基于人类反馈的强化学习
仅使用有监督精调
阿贝尔在 GSM8k和 MATH权威评测集上实现了开源数学模型的最好成绩,具体说来:
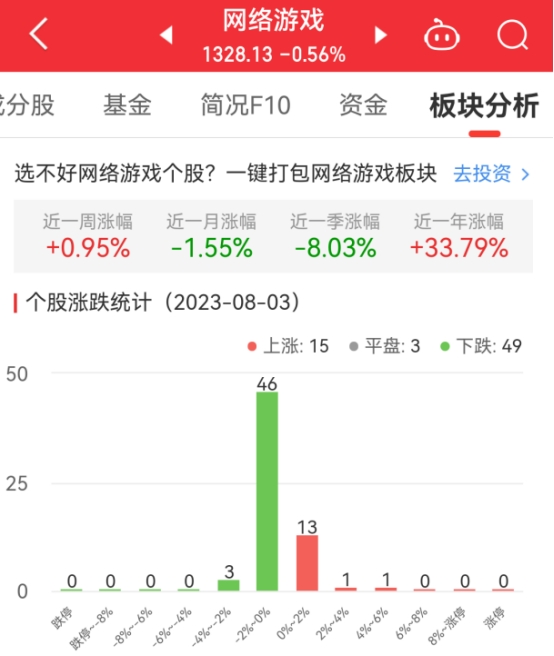
在 GSM8K 上的性能达到了 83.62,超过了许多国外大厂优秀的模型,如 PaLM-1、Minerva、Claude-instant以及 ChatGPT,仅落后于 Google 的最新模型 PaLM-2-Flan1 个百分点;同时也显著高于所有开源国产模型
在具有高难度的数学竞赛问题上,阿贝尔准确率达到了 28.26%,它在其他开源模型中保持了显著领先地位,超过了之前最佳的开源模型 5 个多百分点
7B 和 13B 模型在 GSM8K 和 MATH 两方面以显著优势取得了开源模型性能的最佳
阿贝尔在排行榜前十名中占据了 3 个位置,并且是唯一一家由大学领导的项目
使用作者的方法,不仅在 GSM8K 和 MATH 上取得了出色的成绩,而且在提供新数据集时,迅速达到了最好性能,并且轻松超越了商业模型 MathGPT 和 GPT4。
除了优秀的性能本身,该项目也揭示了:
有监督精调的能力被严重低估,研究人员应该以应有的敬畏和谨慎来对待这个过程。
出色的数学问题解决能力可以通过有监督精调实现的很好,这将在未来对这个方向的探索中引发更多富有想象力的可能性
02
训练方法
为了训练阿贝尔,该团队提出Parental Oversight ,一种监督微调的保姆策略。
Parental Oversight 的核心理念在于,在对大模型进行微调的过程中应该怀着一种敬畏和谨慎的态度,就如同家长在对孩子进行教育时,必须要用最浅显易懂并谨慎的方式进行教导,在稳健成长的同时避免揠苗助长。各种不同的数据和数据的呈现方式 代表的是不同的教育方式,而研究者必须谨慎小心的选择最好的方式教导大模型。
事实上,在 GAI 的背景下,数据结构工程 已经成为一种新的范式。有效的处理数据的方向对大模型在不同下游任务上的成功与否有着极为关键性的影响。从 Parental Oversight 理念出发,在复杂推理任务上取得好的结果,最关键的是要精心策划训练数据,而不是不加选择地使用任何样本进行监督学习。
通过最精确谨慎的监督,协助大模型在复杂推理的下游任务上成长。在有监督精调的训练样本中,不仅应包含正确的答案,还应告诉模型如何从预训练模型的知识中获得正确答案。此外,如果语言模型的知识不足以获得真实答案,监护监督应该帮助模型迅速填补知识上的空白。
03
局限性 & 规划
尽管阿贝尔数学模型在评估的几个数据集上表现优异,但是开发者也总结了它的不足之处:
过拟合:尽管进行了鲁棒性分析,并考虑到数学生成型 AI 天生具有脆弱性,但过于依赖构建 SFT 样本以提高性能可能会不可避免地导致模型出现过拟合现象。尽管如此,团队仍然需要进行更广泛的健壮性分析,并积极探索可以将模型转化为数学通才的训练方法,并进行更全面的跨领域泛化分析。
泛化性:一个好的数学模型不应仅限于解决 GSM8K 和 MATH 数据集上的问题;它应该能够处理各种类型的问题,包括评估不同知识领域并需要不同类型的回答的问题。当前模型的能力不足以泛化到这些多样的场景。
通用性:最终,作者预计大型模型赋予的数学推理能力可以整合到各个领域的聊天机器人中,如医学、法律、物理学、化学等。实现 AGI 的关键在于将强大的数学模型的力量融入其他模型中,而这在当前项目中尚未探索。
多语言性:当前模型的训练数据和基本模型限制了它在除英语以外的语言中提供回应的能力。
高级技术:当前模型主要关注有监督精调,尚未探索奖励模型、RLHF和工具调用等高级技术。
开发者表示已经列出了一系列问题,并用 Github 维护这些限制和潜在解决方案。欢迎大家提出建设性意见和见解。
04
下一步计划
最后,作者也简单用一张图透露了实验室的下一步计划:从 “阿贝尔” 到 “伯努利”。

相关阅读
RelatedReading




猜你喜欢
Guessyoulike
CEO张勇宣布哪吒Aya改装车在BW 2023亮相,即将正式发布

人人皆是改心达人 《女神异闻录:夜幕魅影》首测趣味数据回顾
火山引擎数智平台VeDI获虎啸奖“年度最佳智能营销平台”奖项