2023-09-30 13:40:39 发布人:hao333 阅读( 5888)
一个统一的模型,可以对不同模态输入内容实现理解,并生成文本响应,技术基于 Llama 2,来自 Meta。昨天,多模态大模型 AnyMAL 的研究吸引了 AI ...
一个统一的模型,可以对不同模态输入内容实现理解,并生成文本响应,技术基于 Llama 2,来自 Meta。
昨天,多模态大模型 AnyMAL 的研究吸引了 AI 研究社区的关注。
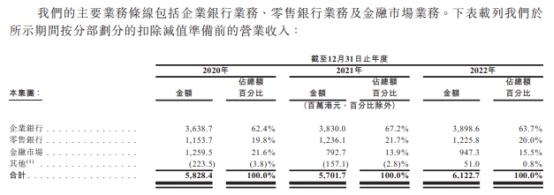
大型语言模型以其巨大的规模和复杂性而闻名,它极大地增强了机器理解和表达人类语言的能力。LLM 的进步使视觉语言领域有了显著进步,弥合了图像编码器和 LLM 之间的差距,将它们的推理能力结合起来。先前的多模态 LLM 研究集中在结合文本和另一种模态的模型上,如文本和图像模型,或者集中在非开源的专有语言模型上。
如果有能够实现多模态的更好方法,将各种模态能够嵌入在 LLM 中使用,会给我们带来不一样的体验吗?
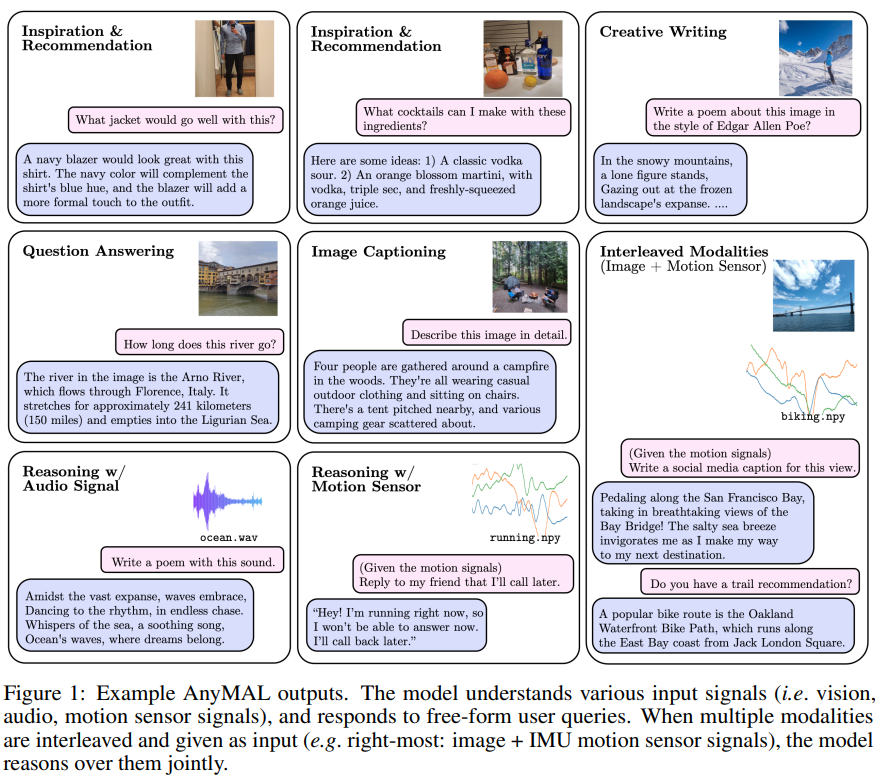
输出示例
为解决这个问题,来自 Meta 的研究人员近日推出了 AnyMAL。这是一个经过训练的多模态编码器集合,可将来自各种模态的数据转换到 LLM 的文本嵌入空间。

论文地址:https://huggingface.co/papers/2309.16058
据介绍,该研究的主要贡献如下:
为构建多模态 LLM 提出了一种高效、可扩展的解决方案。本文提供了在大型数据集上预先训练的投影层,这些数据集包含多种模态,所有数据集都与同一个大模型对齐,从而实现了交错式多模态上下文提示。
本文利用跨三种模式的多模态指令集对模型进行了进一步微调,涵盖了简单 QA 领域之外的各种不受约束的任务。该数据集具有高质量的人工收集指令数据,因此本文也将其作为复杂多模态推理任务的基准。
与现有文献中的模型相比,本文最佳模型在各种任务和模式的自动和人工评估中都取得了很好的零误差性能,在 VQAv2 上提高了 7.0% 的相对准确率,在零误差 COCO 图像字幕上提高了 8.4% 的 CIDEr,在 AudioCaps 上提高了 14.5% 的 CIDEr,创造了新的 SOTA。
方法
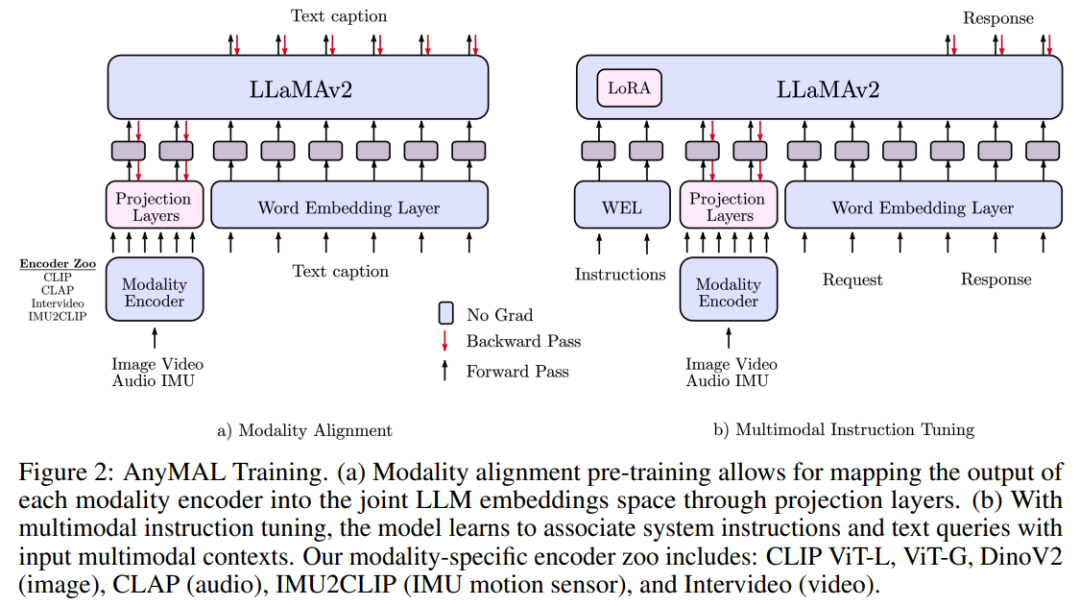
方法概览
预训练模态对齐
本文使用配对的多模态数据对 LLM 进行预训练,从而实现多模态理解能力,如图 2 所示。具体来说,研究为每种模态训练一个轻量级适配器,将输入信号投射到特定 LLM 的文本 token 嵌入空间中。这样,LLM 的文本 token 嵌入空间就变成了一个联合 token 嵌入空间,token 代表文本或其他模态。
对于图像对齐,研究使用了 LAION-2B 数据集的一个干净子集,使用 CAT 方法进行过滤,并对任何可检测的人脸进行模糊处理。对于音频对齐,研究使用 AudioSet 、AudioCaps 和 CLOTHO 数据集。研究还使用 Ego4D 数据集进行 IMU 和文本对齐 。
对于大型数据集,将预训练扩展到 70B 参数模型需要大量资源,通常需要使用 FSDP 封装器在多个 GPU 上对模型进行分片。为了有效地扩展训练规模,本文在多模态设置中实施了量化策略,其中冻结了模型的 LLM 部分,只有模态 tokenizer 是可训练的。这种方法将内存需求缩小了一个数量级。因此, 70B AnyMAL 能够在单个 80GB VRAM GPU 上就完成训练,batch size 为 4。与 FSDP 相比,本文所提出的量化方法只使用了 GPU 资源的一半,却实现了相同的吞吐量。

利用多模态指令数据集进行微调
为了进一步提高模型对不同输入模态的指令跟随能力,研究利用多模态指令调整数据集进行了额外的微调。具体来说,我们将输入连接为
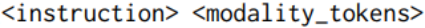
这样响应目标就同时以文本指令和模态输入为基础。研究对以下两种情况进行消减:在不改变 LLM 参数的情况下训练投影层;或使用低级适应进一步调整 LM 行为。研究同时使用人工收集的指令调整数据集和合成数据。
实验及结果
图像标题生成
表 2 显示了在 COCO 和标有「详细描述」 任务的 MM-IT 数据集子集上的零样本图像字幕生成性能。可以看出, AnyMAL 变体在这两个数据集上的表现都明显优于基线。值得注意的是,AnyMAL-13B 和 AnyMAL-70B 变体的性能没有明显差距。这一结果表明,底层 LLM 能力对图像标题生成任务的影响较小,但在很大程度上取决于数据规模和配准方法。

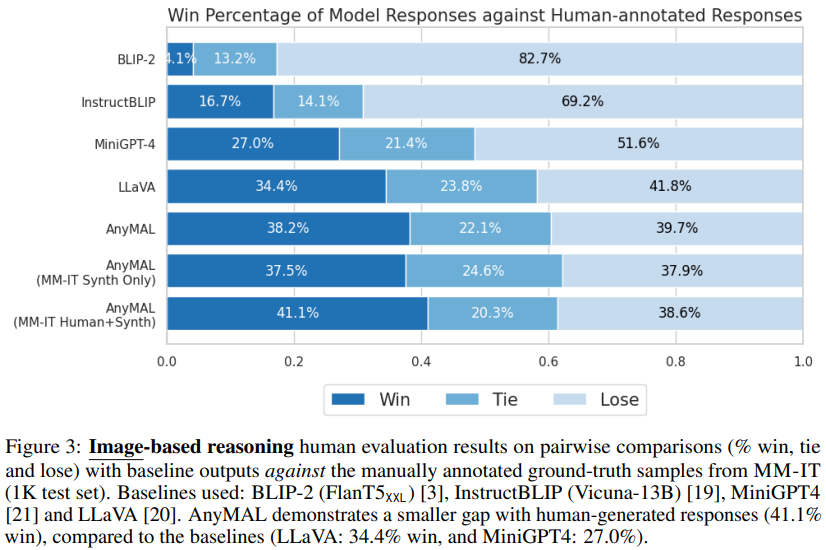
多模态推理任务的人工评估
图 3 显示,与基线相比,AnyMAL 性能强劲,与人工标注的实际样本的差距较小。值得注意的是,使用完整指令集微调的模型表现出最高的优先胜率,显示出与人类标注的响应相当的视觉理解和推理能力。还值得注意的是,BLIP-2 和 InstructBLIP 在这些开放式查询中表现不佳,尽管它们在公开的 VQA 基准测试中表现出色。
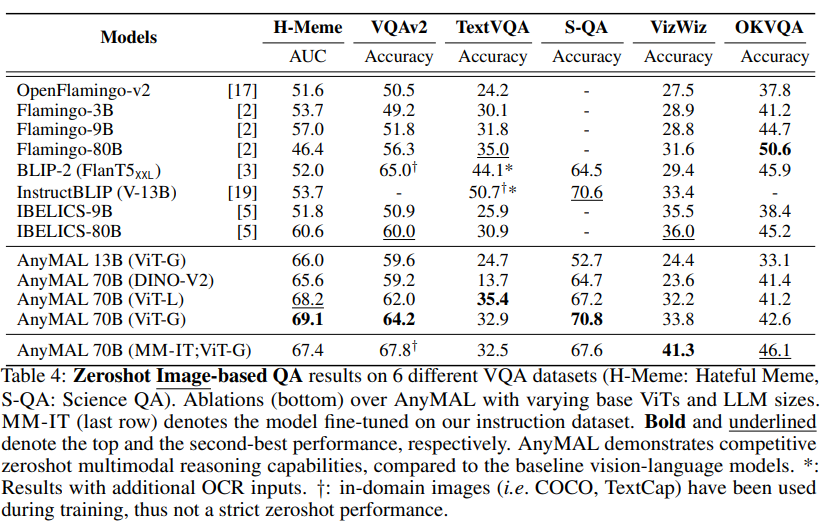
VQA 基准
表 4 显示了在 Hateful Meme 数据集 、VQAv2 、TextVQA 、ScienceQA、VizWiz 和 OKVQA 上的零样本性能,与文献中报告了各自基准上零样本结果的模型进行了比较。研究将重点放在零样本评估上,以便在推理时最好地估计模型在开放式查询上的性能。
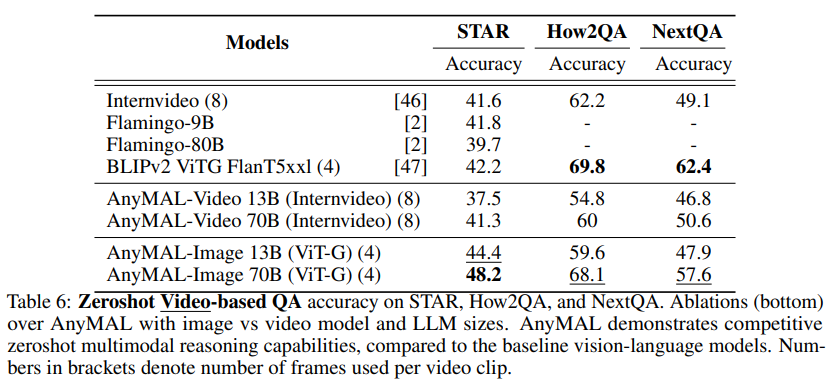
视频 QA 基准
如表 6 所示,研究在三个具有挑战性的视频 QA 基准上对模型进行了评估。
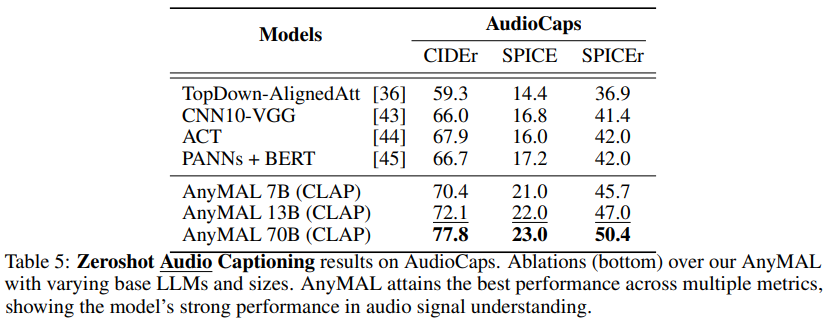
音频字幕生成
表 5 显示了 AudioCaps 基准数据集上的音频字幕生成结果。AnyMAL 的表现明显优于文献中其他最先进的音频字幕模型,这表明所提出的方法不仅适用于视觉,还适用于各种模态。与 7B 和 13B 变体相比,文本 70B 模型表现出了明显的优势。

有趣的是,有人从 AnyMAL 论文提交的方式、类型和时间推测,Meta 似乎正计划通过其新推出的混合现实 / 元宇宙头显来收集多模态数据。说不定这些研究成果在未来会被整合到 Meta 的元宇宙产品线里,或很快进入消费级应用。
相关阅读
RelatedReading猜你喜欢
Guessyoulike