别用GPT-4直出文本摘要!MIT、哥大等发布全新“密度链”提示:实体密度是摘要质量的关键
2023-10-01 13:42:03 发布人:hao333 阅读( 6729)
用密度链提示逐步改善GPT-4摘要中的实体密度,只需三步即可获得「人类级摘要」!ChatGPT发布后,文本生成技术得到飞速发展,大量NLP任务都面临被完全攻克的...
用密度链提示逐步改善GPT-4摘要中的实体密度,只需三步即可获得「人类级摘要」!
ChatGPT发布后,文本生成技术得到飞速发展,大量NLP任务都面临被完全攻克的窘境,尤其是对于缺乏标准答案的「文本摘要」任务来说更是如此。
但如何在摘要中包含「合理的信息量」仍然十分困难:一个好的摘要应该是详细的,以实体为中心的,而非实体密集且难以理解。
为了更好地理解信息量和可理解性之间的权衡,麻省理工学院、哥伦比亚大学等机构的研究人员提出了一个全新的「密度链」提示,可以在不增加摘要文本长度的前提下,对GPT-4生成的实体稀疏摘要进行迭代优化,逐步添加缺失的重要实体。

论文链接:https://arxiv.org/pdf/2309.04269.pdf
开源数据:https://huggingface.co/datasets/griffin/chain_of_density
从实验结果来看,用CoD生成的摘要比由普通提示生成的GPT-4摘要更抽象,表现出更多的融合性以及更少的lead bias
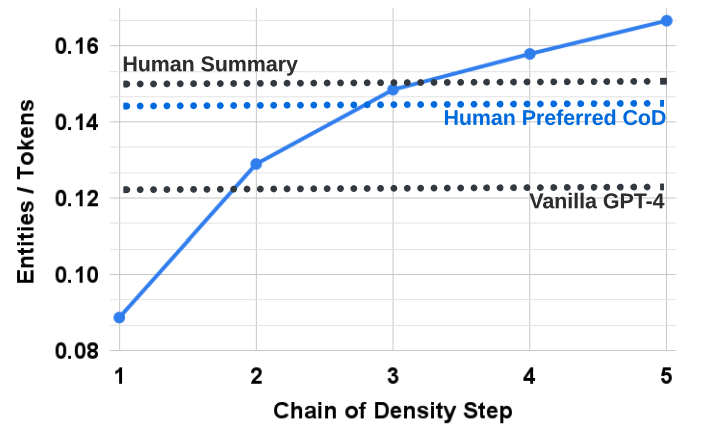
在对100篇CNN DailyMail文章进行人类偏好研究后可以发现,人类也更倾向于选择实体更密集的摘要结果,与人工编写摘要的实体密度相近。
研究人员开源了500篇带标注的CoD摘要,以及5000篇无标注的摘要数据。
01
迭代改进文本摘要
提示
任务目标是使用GPT-4生成一组具有「不同信息密度水平」的摘要,同时还要控制文本的长度。
研究人员提出密度链提示来生成一个初始摘要,并逐渐使实体密度越来越大。
具体来说,在固定的迭代轮数下,识别出源文本中一组独特的、显著的实体,并融合到先前的摘要中而不增加文本长度。

首次生成的摘要是实体稀疏的,只关注1-3个初始实体;为了保持相同的文本长度,同时增加涵盖的实体数量,需要明确鼓励抽象、融合和压缩,而不是从之前的摘要中删除有意义的内容。
研究人员没有规定实体的类型,而是简单地将缺失实体定义为:
相关:与主体故事相关;
具体:描述性但简明扼要;
新颖:没有出现在之前的摘要中;
忠实:存在于原文中;
任何地方:可以出现在文章中的任意位置。
在数据选择上,研究人员从CNN/DailyMail摘要测试集中随机抽取100篇文章来生成CoD摘要。
然后将CoD摘要统计数据与人工编写的条目风格的参考摘要以及GPT-4在常规提示下生成的摘要进行对比,其中提示词为「写一篇非常简短的文章摘要,不超过70个词」。
预期token长度设置为与CoD摘要的token长度相匹配。
02
统计结果
直接统计指标
使用NLTK计算token数量,使用Spacy2测量独特的实体数量,并计算实体密度比率。
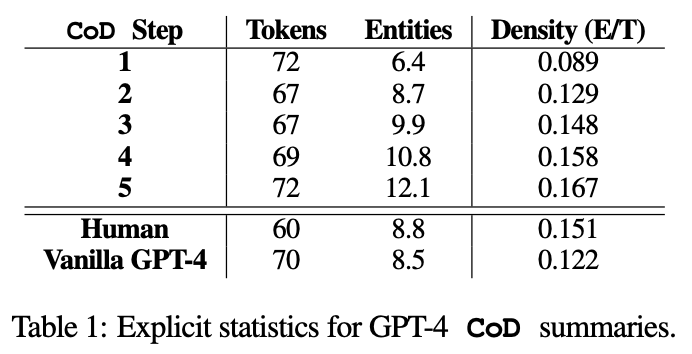
CoD提示很大程度上限制了生成摘要的预期token数量,可以看到,从第二步开始从冗长的初始摘要中逐渐删除不必要的单词,使得文本长度平均减少5个token。
实体密度也随之上升,最开始是0.089,低于人类和GPT-4的结果,而在5步操作后密度上升到0.167。
间接统计指标
使用抽取密度来衡量文本的抽象性,预期文本应该随CoD的迭代进展而增加。
使用「摘要句子与源文本对齐数量」作为概念融合指标,其中对齐算法使用「相对ROUGE增益」,将源句子与目标句子对齐,直到额外添加的句子不会继续提升相对ROUGE增益为止,预期融合应该逐渐增加。
使用「摘要内容在源文本中的位置」作为内容分布指标,具体测量方法为所有对齐源句子的平均排序,预期CoD摘要最初表现出明显的Lead Bias,后续逐渐开始从文章的中间和结尾部分引入实体。
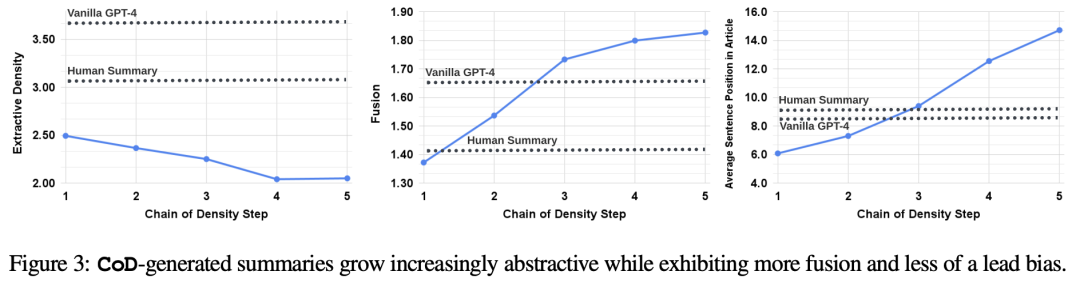
统计结果也验证了预期结果的正确性:抽象性随着重写过程而逐渐增加、融合率上升、摘要开始纳入文章中间和结尾的内容。
并且,所有CoD摘要都比手工编写和基线模型生成的摘要更加抽象。
03
实验结果
为了更好地理解CoD摘要的权衡,我们用GPT-4进行了一项基于偏好的人体研究和一项基于评级的评估。
人类偏好评估
研究人员主要以评估致密化对人类整体质量评估的影响。
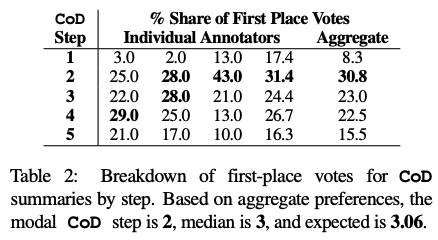
具体来说,输入100篇文章,可以得到「5个步骤*100=总计500个摘要」,向四位标注人员随机展示摘要结果,并根据原文忠实度、清晰性、准确性、目的性、简洁性和风格对摘要进行评估。

从票选结果来看,第二个CoD步骤获得了最高评价,再结合之前平均密度的实验结果,可以大体推断出人类更倾向于选择实体密度约为15%的文本摘要,显著高于GPT-4生成的摘要。
自动评估指标
最近一些工作已经证明了GPT-4的评估与人类评估结果之间的相关性非常高,甚至有可能在部分标注任务上比众包工作者的表现还要好。
作为人工评估的补充,研究人员提出使用GPT-4从5个方面对CoD摘要进行评级:信息量、质量、连贯性、归因和整体性。
使用的指令模版为:
Article: {{Article}}
Summary: {{Summary}}
Please rate the summary with respect to {{Dimension}}.
{{Definition}}
其中各个指标的定义为:
信息量:信息量丰富的摘要可以抓住文章中的重要信息,并准确简洁地呈现出来。
质量:高质量的摘要是可理解的。
连贯性:连贯一致的摘要结构严谨,组织有序。
归因:摘要中的所有信息是否完全归因文章?
总体偏好:一个好的摘要应该以简洁、逻辑和连贯的方式传达文章的主要观点。
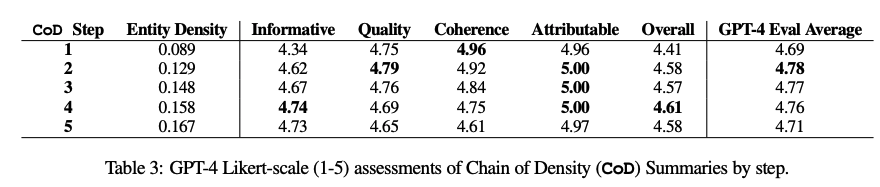
实验结果表明,致密化与信息量相关,但得分在第4步时达到峰值;质量和连贯性的下降更快;所有摘要均被视为归因自源文章;总体得分倾向于更密集和更翔实的总结,第4步得分最高。平均而言,第一个和最后一个CoD步骤最不受青睐,而中间三个步骤很接近。
定性分析
摘要的连贯性/可读性和信息量之间在迭代的过程中需要权衡。

上面例子中展示了两个CoD步骤,分别包含更细节的内容和更粗略的内容。
平均而言,中间步骤的CoD摘要可以更好地实现平衡,但如何精确定义和量化这种平衡目前还没有工作。
相关阅读
RelatedReading




猜你喜欢
Guessyoulike
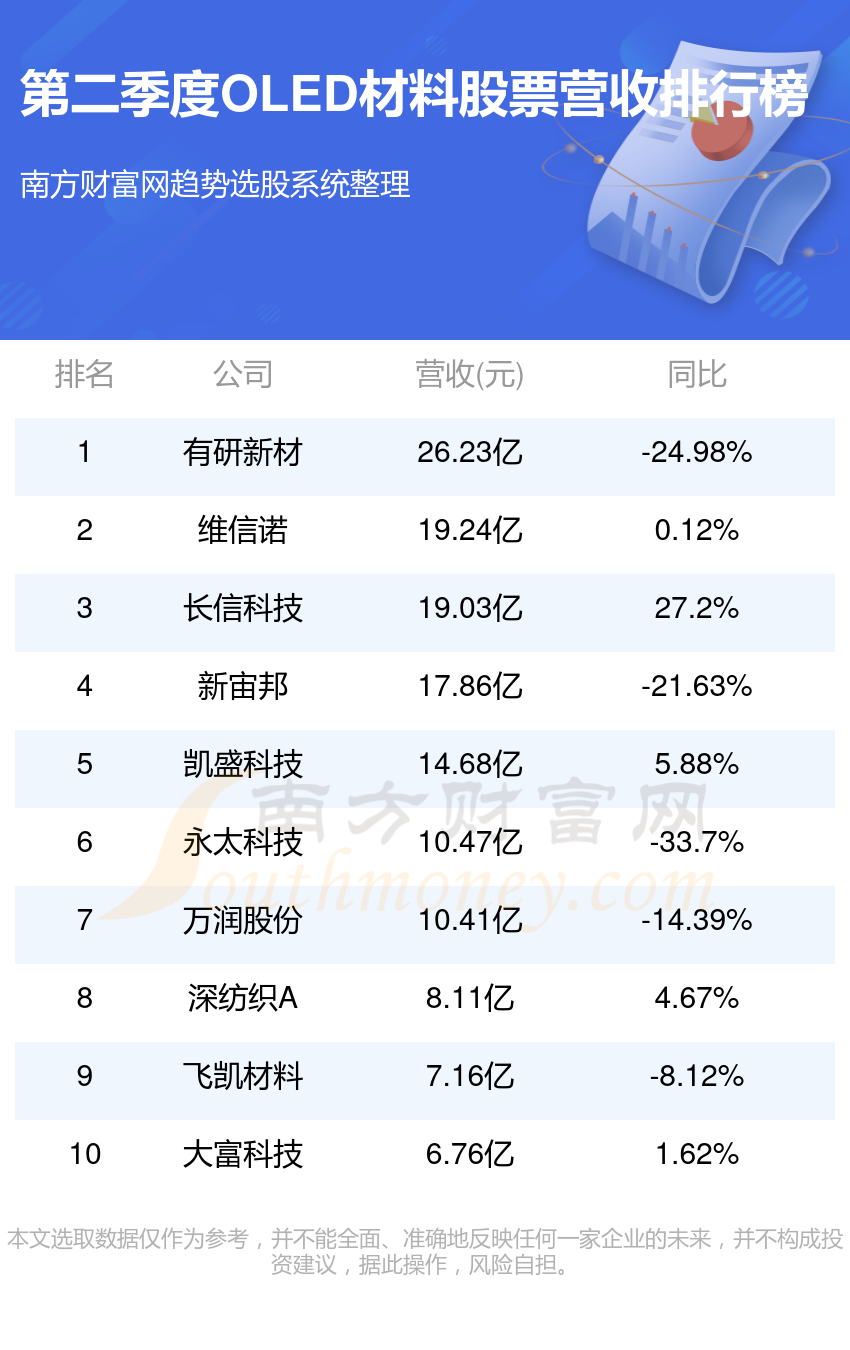
OLED3大龙头股(附龙头股名单)
价格突然大跳水!网友:心态崩了

IPO这件事,盒马和市场都没准备好