Chiplet:实现AI大模型算力跨越的关键之道
2023-10-09 15:20:07 发布人:hao333 阅读( 6585)
集微网报道 以ChatGPT为代表的AI应用蓬勃发展,对上游AI芯片算力提出了更高的要求。半导体大厂通过不断提升制程工艺和扩大芯片面积,推出更高算力的芯片产品加...
集微网报道 以ChatGPT为代表的AI应用蓬勃发展,对上游AI芯片算力提出了更高的要求。半导体大厂通过不断提升制程工艺和扩大芯片面积,推出更高算力的芯片产品加以应对。研究显示,当5nm芯片的面积达到200mm2以上,采用Chiplet方案成本将低于单颗SoC,同时也减少了因芯片面积增加而带来的良率损失。除了成本和良率的优势,Chiplet技术还带来了高速的Die to Die互连,使得芯片设计厂商可以将多颗芯粒集成在一块芯片之中,实现算力上的大幅提升。对此,有越来越多厂商意识到,Chiplet将是AI芯片实现算力跨越的破局之道。
Chiplet为算力增长赋能
Chiplet通常被翻译为“芯粒”或“小芯片”,通过将原来集成在一颗系统级单芯片中的多个单元分拆开来,独立成为多个具特定功能的芯粒,分开制造后再通过先进封装技术将彼此互联,最终集成封装为一个系统芯片组。对此,芯和半导体联合创始人、高级副总裁代文亮指出,Chiplet是先进工艺制程逼近物理极限,芯片PPA提升放缓,经济效益降低的大背景下,应运而生的。

目前,芯片面积已经接近光罩尺寸的极限,单芯片尺寸不能超过1个光罩面积800mm2。同时,芯片的尺寸越大,落入晶圆坏点位置的概率也就越高,良率越低。更小的芯粒尺寸可以带来更高的良率,突破光罩尺寸限制,降低制造成本。芯粒还拥有更多工艺节点可以选择,可以将最佳节点实现的芯粒进行混合集成,从而提高研发效率,摊薄NRE成本,缩短上市周期。人们大多听说过“摩尔定律”。实际上,戈登·摩尔在1965年还有一个预言:“事实可能会证明,用小型功能构建大型系统,分别进行封装和互连,性价比会更高。”
当GPT-4首次支持多模态后,文本、图像、视频及更多形态的数据都成为用于模型训练的数据。从训练到推理,从数据中心到边缘,AI引爆的数据多模态化浪潮使得业界意识到原有的算力明显不够。如果说过去对算力的需求是以倍数增长,现在就是呈现指数级态势。这就对半导体行业提出更高挑战。
从当前的发展态势来看,Chiplet或许正是满足当下算力需求的关键技术。一方面,通过Die to Die互联和Fabric互联网络,能够将更多算力单元高密度、高效率、低功耗地连接在一起,从而实现超大规模计算。另一方面,通过将CPU、GPU、NPU高速连接在同一个系统中,实现芯片级异构,可以极大提高异构核之间的传输速率,降低数据访问功耗,提高数据的处理速度,降低存储访问功耗,满足大模型参数需求。
进入规模化应用阶段
Chiplet技术方兴未艾,全球半导体顶尖公司都在积极推出自己的产品。特斯拉Dojo深度学习和模型训练芯片,采用Chiplet进行系统垂直重构,每个训练Computing Tile含25颗D1 Chiplet,6个Tile+20个接口处理器形成Dojo一个Tray。AMD MI300 APU加速显卡为全球首个CPU+GPU Chiplet,利用3D封装技术将CPU和加速计算单元集成在一起,整颗芯片集成1460亿颗晶体管,5种/21颗Chiplet。英伟达的Ampere A100 GPU采用GPU+6xHBM,通过封装技术在中介层实现GPU和HBM之间的高速互联。超摩科技联合创始人、技术市场副总裁邹桐表示,ChipLet已经进入规模化应用阶段,应用于高性能计算芯片当中。
值得注意的是,在边缘侧大模型推理,对于边缘算力的需求也是未来一大趋势。与云计算的数据中心架构相比,大模型在边缘端的智能计算是在一个已经训练好、有基本智能水平的模型基础上,当边缘端具备多模态大模型的离线学习进化能力时,本地模型将变得私人定制化,数据也无需上传云端。这部分推理与训练微调过程主要依赖边缘大模型的AI算力。

根据原粒半导体联合创始人原钢的介绍,针对边缘侧单任务的大模型场景,可以把模型切分到不同Chiplet进行并行计算,通过在预训练模型的基础上进行额外训练,使其适应特定任务。大模型的边缘端微调,可使用本地存储的私有数据,或者本地新采集的数据。“SoC主控+AI Chiplet”组合可有效复用芯片主控,显著降低成本,快速满足各类规格需求。这将是未来该领域的重要发展方向。
核心目标是降成本提性能
当前,Chiplet应用的局限性依然明显。根据中兴微高速互联总工程师吴枫介绍,目前Chiplet仍以国际大厂的垂直体系为主,每个厂家都在依照自己的产品体系,设计相关封闭的系统。如果想要实现不同平台间的Die to Die互联,仍然有待完善互联标准。此外,Chiplet初期成本依然高企,需要有确定和相当的市场容量才能支撑。代文亮也指出,存在Die互连、先进封装3D异构集成、设计流程及工具等挑战,是Chiplet实现的核心问题。
Die-to-Die互连是一项核心工作。标准协议统一化是行业发展的大趋势。Chiplet增加了互连的复杂性,但只有实现了Chiplet之间的标准化,才能有效扩大生态圈,提高复用并降低成本。对此,吴枫认为,要加强通用的Die to Die PHY IP的开发,为Chiplet提供高带宽,低功耗、低延迟的物理层连接。在生态建设层面,应设立物理层标准,规范尺寸、摆放方式、电气、逻辑层协议、帧格式、流程等,加强一致性和兼容性。在生态方面,应加强IP供应商、EDA设计、验证和仿真工具、测试方案和测试工具的协同。系统级/Chiplet是多团队、多芯粒、多厂商、多工艺节点、多功能模块、多材料、多工具等要素融合的产品设计,需要从顶层出发协同优化整个系统。

代文亮则强调,要加强先进封装3D异构集成技术的研发。3D异构集成是Chiplet实现的基础,面临诸多设计挑战,比如互连、散热、良率、翘曲、无源器件集成、寄生效率、成本、可靠性等。通过封装技术才能有效实现多Chiplet的集成,包括高密度先进封装的设计、生产、验证,高速通道的设计、验证,供电方案、散热方案、应力方案、可靠性等,为Chiplet之间提供高密度高速的互联,支持大电流供电。
应用Chiplet技术的核心目的是降低成本与提高性能。在降低成本方面,Chiplet复用是降低成本的有效手段。在提高性能方面,核心则是重构系统,将计算、存储模块拉近,实现系统设计、软件适配等多方面的优化。借助Chiplet技术进行系统级协同设计,可以在多样化的场景和需求下,实现整个芯片/系统的PPA最优化。开发流程需要匹配Chiplet架构,Chiplet之间需要协同设计、仿真、验证,进而提高交付效率和交付质量。
相关阅读
RelatedReading



猜你喜欢
Guessyoulike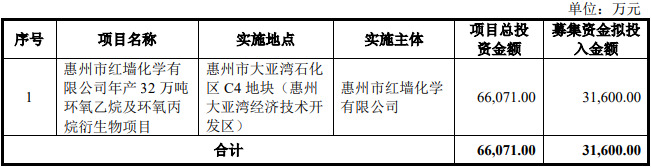
红墙股份不超3.2亿可转债获深交所通过 中泰证券建功

封测龙头股,四大封测龙头股一览(9/22)
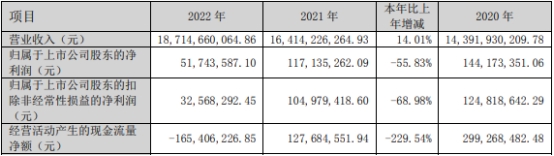
益客食品上市当年净利降56%受处罚4次 中信证券保荐