百川VS智谱,谁是中国的OpenAI?
2023-10-20 21:24:39 发布人:hao333 阅读( 7485)
文|郝 鑫编|刘雨琦6月初,外媒曾发出了“谁是中国的OpenAI”的拷问,经历了大模型创业潮之后,大浪淘沙,最终留下的不过寥寥数人。清华大学几个十字路口外的搜狐...

文|郝 鑫
编|刘雨琦
6月初,外媒曾发出了“谁是中国的OpenAI”的拷问,经历了大模型创业潮之后,大浪淘沙,最终留下的不过寥寥数人。
清华大学几个十字路口外的搜狐大厦,二层是明星创业者王小川的百川智能,七层到十一层是学院派出身的智谱AI。二者在经历了市场的检验后,成为了最有希望的两个候选人。
同一栋楼里的争夺战,似乎已经悄然打响了。
从融资上看,智谱AI和百川智能都在今年,完成了多轮大额融资。
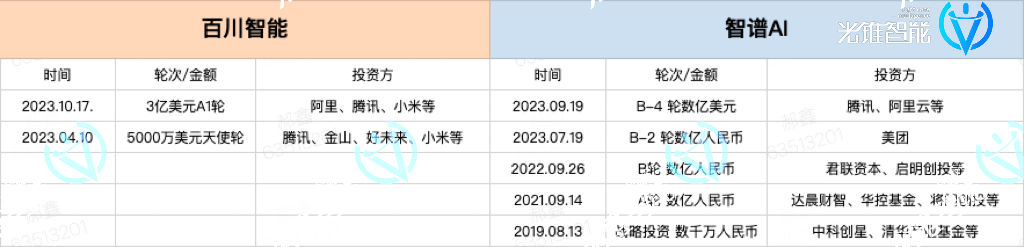
今年,智谱AI累计总融资金额超25亿元人民币,百川智能总融资金额达到3.5亿美元,可支持百川模型与LLAMA模型、百川模型不同模块之间的随意切换,比如用LLAMA训练一个模型后,无需修改,就直接能把这个模型放到百川中使用。这也解释了现在多数互联网大厂使用百川模型,和云厂商引入百川系列模型的原因。
历史走过的路,既通向过去,也通向未来,王小川的大模型创业便是如此。
源于搜狗创始人的身份和搜索技术经验,创业初期,王小川获得了不少人这样的评价,“小川,是最适合搞大模型的啊”。
在搜索经验和框架中构建大模型成为了百川智能的底色。
百川智能技术联创陈炜鹏曾表示,搜索研发与大模型开发有许多类似之处,“百川智能将搜索的经验快速迁移到大模型的研发中,这就类似一个'造火箭'系统化工程,将复杂的系统做拆解,通过过程评估来推动团队的协同,提升团队的效果”。
王小川也在发布会现场谈道:“因为百川智能之前有搜索基因,因此天然懂得如何从万亿网页中间去精选最好的页面,可以做到去重、反垃圾。在数据处理中,百川智能也借鉴了之前搜索的经验,能小时级完成千亿数据的清洗和去重工作”。
其大模型搜索的内核在Baichuan-53B中展现得淋漓尽致。在处理大模型“幻觉”问题上,结合搜索技术沉淀,百川智能在信息获取、提升数据质量、搜索增强等方面做了优化。
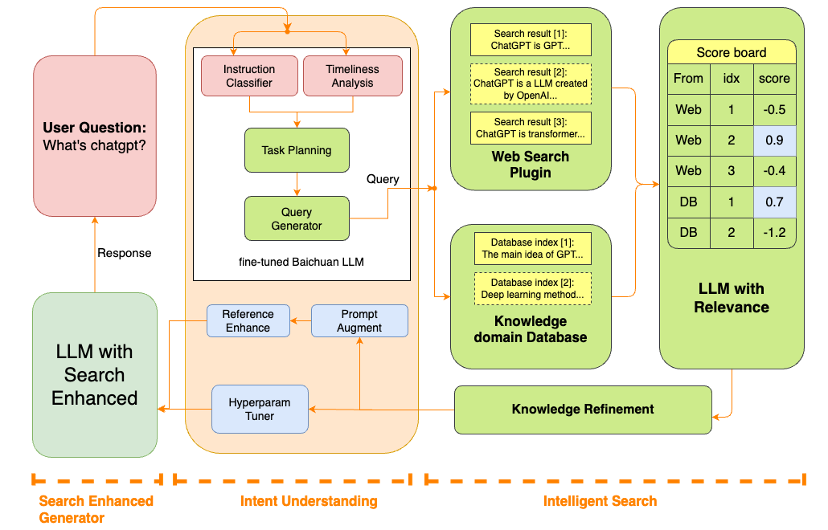
在提升数据质量上,百川智能的核心思路是“始终取优”,以低质、优质为标准将数据进行分类,确保Baichuan2-53B始终使用优质数据进行预训练;在信息获取方面,Baichuan2-53B对多个模块进行了升级,包括指令意图理解、智能搜索和结果增强等关键组件,通过深入理解用户指令,精确驱动查询词的搜索,最终结合大语言模型技术,优化模型结果生成的可靠性。
尽管以开源为始,但百川智能已经开始探索商业化路径。官方资料显示,百川智能的目标有两个方向,横向维度的目标是“构建中国最好的大模型底座”,纵向维度的目标是在搜索、多模态、教育、医疗等领域增强。
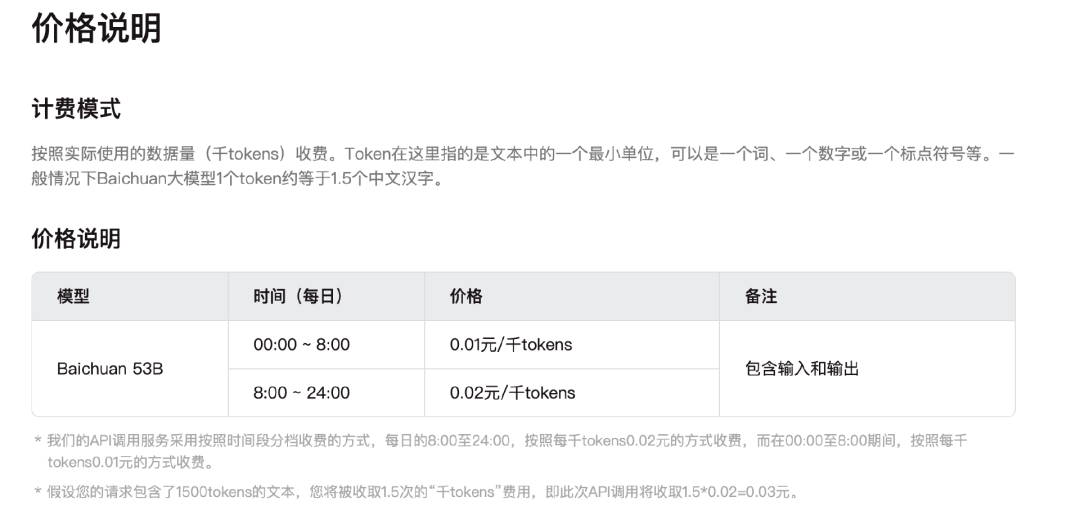
如今的商业化,集中在了Baichuan2-53B,官网显示,该模型的API调取采用了分时段收费标准。0:00-8:00收费为0.01元/千tokens,8:00-24:00收费为0.02元/千token,相比较之下,白天的收费价格要高于晚上。
结尾
争论谁是中国的OpenAI这一问题,在大模型发展的早期没有太大的意义。智谱AI、百川智能等诸多初创公司已经意识到盲目跟随OpenAI的脚步并不可取,例如智谱AI已经明确了“不做中国GPT”的技术路径。再者,在开源蔚然成风,正在形成包围之势的当下,OpenAI的绝对技术优势地位似乎也并不是牢不可破。
智谱AI、百川智能曾不约而同地提到,超级应用才是更广阔的市场,也是中国大模型企业的舒适区,不再停留原地,比如一位接近智谱AI人士曾向媒体爆料,智谱AI团队已经坚定2B路线,瞄准信创市场,并在5个月里,快速扩张团队,从200人增至500人,以为后续的2B业务储备人力。
而百川智能在商业化路径上,则选择了参照Llama2的开源生态,也已经开始小步迭代。
肉眼可见的是,仅半年时间,百川智能和智谱AI就已经走过了技术无人区,来到了面向产业落地的商业化阶段。对比AI1.0的创业热潮,技术打磨期长达3年,而正是由于在商业落地上受阻,才导致了一大批AI公司在2022年集体走向没落,倒在了黎明前。
吸取了上一阶段的教训,同时也源于大模型技术的通用性更便于落地,以百川智能和智谱AI为代表的创业公司,正养兵秣马,为下一阶段做好技术、产品和人才储备。
不过,场马拉松也才听到第一声枪响,言结果为时尚早。但至少对赛道的第一阶段分解已经完成,目标明确后,比拼的更是耐心和毅力。这一点,无论对于百川智能、智谱AI还是OpenAI,都一样。
-
上一篇:消失的拉夏贝尔
相关阅读
RelatedReading





猜你喜欢
Guessyoulike
高水平!“现象级”!各方称赞杭州亚运会开幕式

苹果iPhone 15/Pro手机USB-C接口支持4.5W反向充电,最高USB3.2 Gen 2数据传输速度

阿特斯涨20% 机构净买入1.72亿元