世界上最快的AI芯片,是何方神圣?
2023-10-26 17:25:58 发布人:hao333 阅读( 2340)
作者:付斌,题图来自:视觉中国这两天,IBM低调地发了一个新闻,推出了一款类脑芯片“北极”,对比4nm节点实现的Nvidia H100 GPU相比,NorthP...
作者:付斌,题图来自:视觉中国
这两天,IBM低调地发了一个新闻,推出了一款类脑芯片“北极”,对比4nm节点实现的Nvidia H100 GPU相比,NorthPole的能效提高了五倍,成为当之无愧是现在世界最强的AI芯片。
如此逆天的性能,但在国内,关于这款芯片的新闻却寥寥无几。那么,它究竟是何方神圣?
把脑子装进芯片,就行了?
首先,IBM的“北极”NorthPole是一种类脑芯片,我们需要先了解什么是类脑芯片。
所谓类脑芯片,顾名思义,就是一种高度模拟人脑计算原理的芯片,基于对现代神经科学的理解,反复思考如何从晶体管到架构设计,算法以及软件来模仿人脑的运算。如果把类脑芯片做得更像人脑,就会被赋予一个新的名字——神经形态计算。
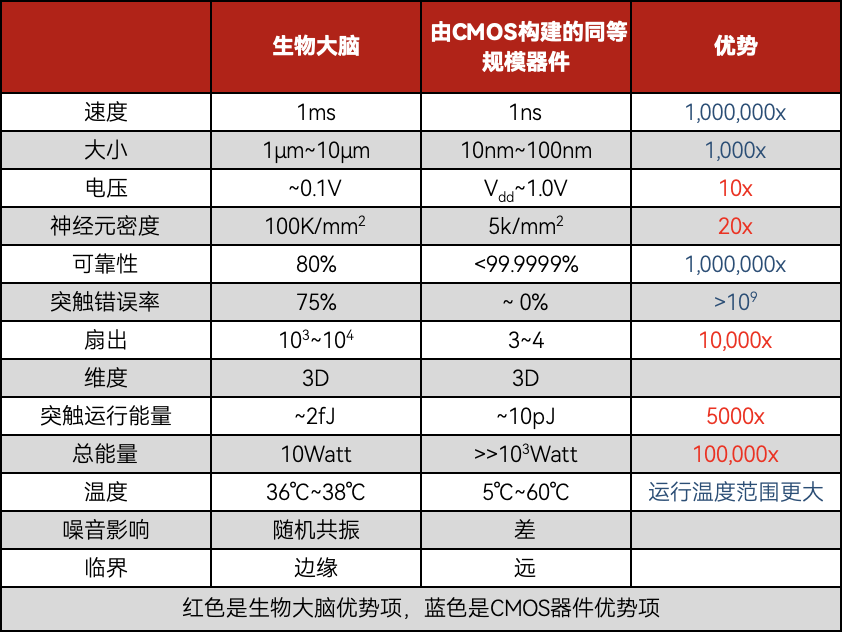
人类的思考方法与现在传统的芯片存在许多区别,比如,人没有单独的存储器,没有动态随机存取存储器,没有哈希层级结构,没有共享存储器等等。
“存储”和“处理器”错综复杂地深绕在人脑里,在人脑的结构中有“神经元”的存在。在电脑中,以数字化核心相互交流基于事件的信息,叫做脉冲,这点和人脑传递信息的方式相似。
人类便从人脑中得到灵感,从而创造出这样的芯片,来提升性能,成为真正的“人工智能”,甚至无限接近人类,获得思考能力。
当然,人脑很复杂,而且人们所制造出来的IC器件,也存在优势,所以人们最终目标就是把这二者的优势融合起来。
总而言之,用人话来解释,类脑芯片,就是结合生物大脑和人造器件各自优点而设计制造出来的一种芯片,而它也会像人一样思考,自我学习。
想造一颗这样的芯片,可不是光变器件结构就行的,而是从材料、器件、电路、架构带动算法和应用改变的。一言蔽之,就是集合各种最先进的技术,才能造出这样的芯片。
虽然实现路径很多,但奈何这种芯片技术难度太大了,且不说好不好造,设计出来就很难了,所以目前也在开拓阶段,都还无法达到商业化水平。
但笔者了解到,之所以类脑芯片还未形成大规模商业化,一是因为设计难题依存,就拿英特尔、IBM都看好的CMOS型,多块全数字异步设计的芯片互联、芯片连接的有效性和时效性以及软件层互连计算、分布式计算和灵活分区等问题都难以解决;二是制造、软件和生态都要完全推翻,虽然硅基晶体管路线部分可复用,但底层不可能完全照搬,这就进一步加剧大规模商业化难度。
那,我们为啥费大力气折腾类脑芯片?
类脑芯片实在太香了,笔者了解到,某些情况下,完美的神经形态芯片可以用比传统解决方案低1000倍的能耗来解决问题,这意味着我们可以在固定的功耗预算下,打包更多的芯片来解决更大规模的问题。
类脑芯片的超高能效比足够让我们牟足力气研究和突破。拿一个最典型的例子来看,AlphaGo下棋打败了人类,但人类只用了20瓦的大脑能耗,而AlphaGo是2万瓦。
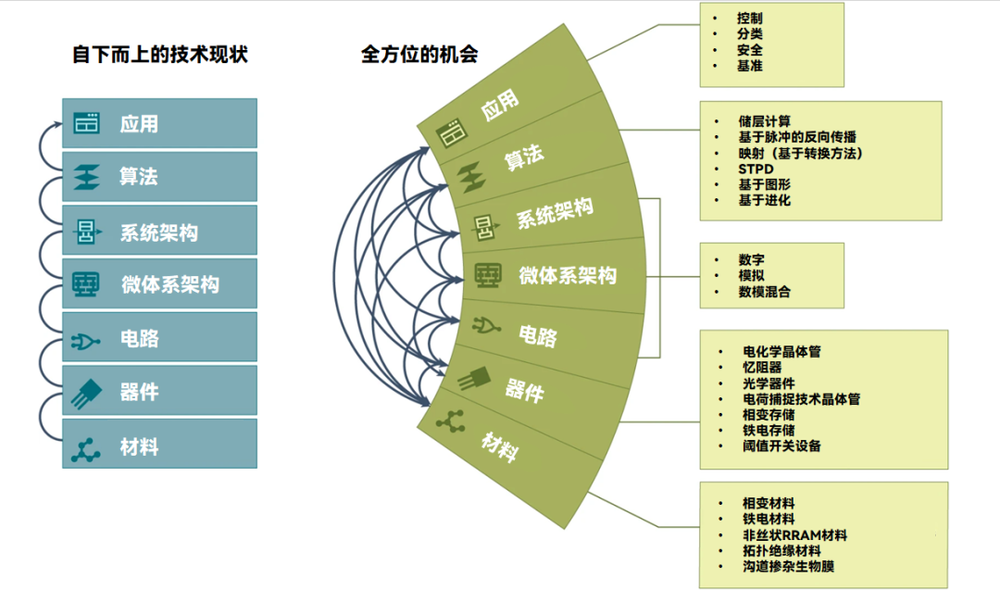
神经形态芯片涉及的领域和机会,图源丨Nature Computational Science
结构上,目前全世界的类脑芯片基本都一致,都是由神经元计算、突触权重存储、路由通信三部分构成,同时采用与脉冲神经网络模型。
但依据材料、器件、电路,分为模拟电路主导的神经形态系统、全数字电路神经系统、基于新型器件的数模混合神经形态系统三种流派。
全球范围内,参与神经形态计算芯片开发的机构主要包括三类:英特尔、IBM、高通等为代表的科技巨头企业,斯坦福、清华为代表的高校/研究机构以及初创企业。
根据笔者之前与英特尔研究院对话中获悉,数字CMOS型是目前最易产业化的形式,一方面,技术和制造成熟度高,另一方面,不存在模拟电路的一些顾虑和限制。
当然,需要强调的是,数字CMOS型还只是最初阶的类脑芯片,还算不上完全模拟人脑的神经形态器件,只能算是一种借鉴神经形态理念的一种芯片。但光是借鉴人脑,这种芯片就能够碾压世界上任何一种芯片。IBM的NorthPole就是这样的数字CMOS型的类脑芯片。
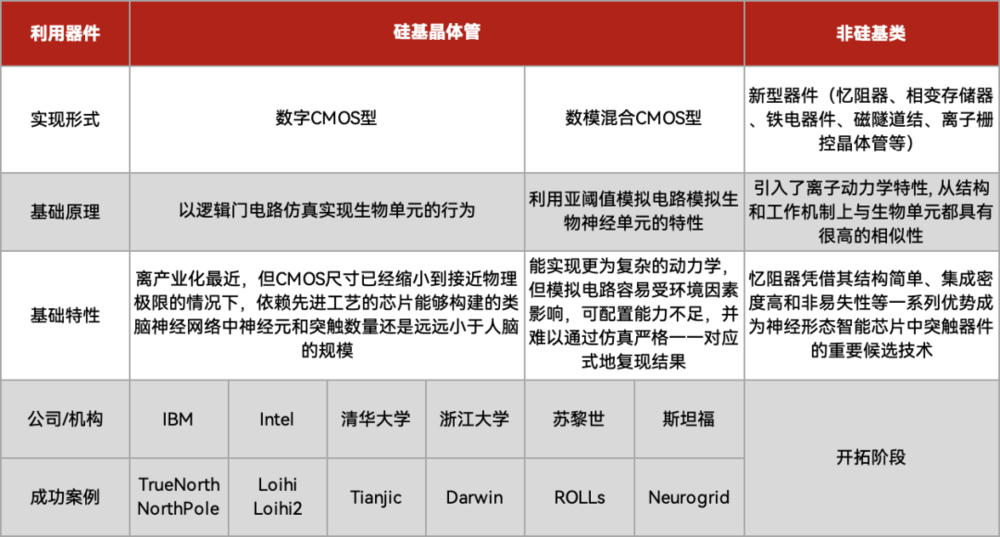
类脑芯片主要类型和研发进度,制表丨电子工程世界
IBM的芯片,什么水平?
先说结论,应该是迄今为止,人类水平最高的类脑芯片了,对于类脑芯片研究又上了一个台阶。
2008年,IBM就开始研究类脑计算了,2011年有了第一次突破性成果:IBM的第一代神经突触计算机芯片。研究人员制造出两个这样的芯片模型:一颗包含262,144个可编程突触,一颗则包含65,536个可学习突触,通过测试展示其可执行导航、机器视觉、模式识别、关联记忆和分类等简单功能。
直到2014年,IBM在《科学》杂志发表了一篇文章,向全世界展示了划时代的技术进展:一个符合DARPA SyNAPSE项目指标的、拥有100万神经元的类脑处理器,即TureNorth,在当时掀起了类脑芯片研究热潮。
沉寂8年,“北极”问世,NorthPole就是建立在IBM最后一颗类脑芯片TrueNorth基础之上,彼时TrueNorth就有这比传统微处理器低四个数量级的能效比,对比一下二者,就能很直观感受到IBM技术的变化:
单个TrueNorth芯片包含4096个计算核心,可以实现神经突触和神经元排列的动态映射。IBM TrueNorth系统的一个吸引人的功能是,单个芯片由54亿个晶体管组成,仅消耗70mW的功率密度,仅占传统计算单元的1/10000;
NorthPole采用12nm节点工艺制造,在800平方毫米内集成了220亿个晶体管,有256个内核,在8位精度下,每个内核每个周期可执行2048次运算;在4位和2位精度下,运算次数有可能分别增加一倍和四倍。运行基于人工智能驱动的图像识别算法速度是目前市场上同类芯片的22倍,能效是同类芯片的25倍。在不使用最先进工艺的情况下,NorthPole芯片能耗是使用最先进技术的人工智能芯片的1/5。总体而言,NorthPole的速度大约是TrueNorth的4000倍。

图/IBM
结构方面,NorthPole与TrueNorth一样,由一个大型计算单元阵列组成,每个单元都包含本地内存和代码执行能力。
计算资源方面,NorthPole每个单元都经过优化,可执行精度较低的计算,精度从 2 bit到8 bit 不等。为保证执行单元使用,它们不能根据变量值执行条件分支,也就是说,使用者代码不能包含if语句。这种简单的执行方式使每个计算单元都能进行大规模并行执行。在2 bit精度下,每个单元可并行执行8000多次计算。
存储方面,所有的内存都被封装在一颗芯片内, 这意味着每个内核都可以轻松地访问芯片上的内存。设备外部来看,NorthPole看起来像是一个主动存储芯片,这有助于将NorthPole集成到系统中。
不止如此,这款NorthPole目前采用的是12nm纳米节点工艺制造,目前CPU最先进的技术是3nm,而IBM还在研发2nm纳米节点技术,如果用上2nm,可能IBM的类脑芯片性能还会再提升很大档次。

图/IBM
NorthPole的潜在应用主要包括图像和视频分析、语音识别以及Transformer神经网络,这些网络是为ChatGPT等聊天机器人提供支持的大型语言模型。这些人工智能任务可能会用于自动驾驶汽车、机器人、数字助理和卫星观测等领域。
某些应用程序需要的神经网络太大,无法安装在单个NorthPole芯片上。在这种情况下,这些网络可以分解为更小的部分,并分布在多个NorthPole芯片上。
而NorthPole的超高能效比,意味着它不需要笨重的液体冷却系统来运行,风扇和散热器就足够了,而它也可以部署在更小的空间中。
国内开始研究类脑芯片了吗?
如此强大的芯片,国内也早已有所布局。
国内研究则包括清华大学、浙江大学、复旦大学、中科院等顶级学府和机构,同时近两年不断涌现初创公司,如灵汐科技、时识科技、中科神经形态等。其中以清华大学的天机芯和浙江大学的达尔文芯片最具代表性。

具体而言,国内的主要成果包括:
清华大学2015年开发的第一代天机芯采用110nm工艺,2017年,第二代天机芯开始取得先进成果,基于28nm工艺制成,由156个功能核心FCore组成,包含约4万个神经元和1000万个突触。相比第一代,密度提升20%,速度提高至少10倍,带宽提高至少100倍,此外,清华大学还自主研发了软件工具链,支持从深度学习框架到天机芯的自动映射和编译。根据清华大学的计划,下一代天机芯将是14nm或更先进的工艺,且功能会强大更多;
浙江大学联合之江实验室共同研制的类脑计算机,其神经元数量与小鼠大脑神经元数量规模相当。该计算机包含792颗达尔文2代芯片,支持1.2亿个脉冲神经元、720亿个神经突触,而其典型运行功耗仅为350W~500W;
2020年10月,清华大学计算机系张悠慧团队精仪系施路平团队与合作者在《自然》杂志发文首次提出“类脑计算完备性”以及软硬件去耦合的类脑计算系统层次结构;
2023年9月,中国科学院计算技术研究所尤海航研究员和唐光明研究员带领的研究团队研制了超导神经形态处理器原型芯片“苏轼”,它是一款基于超导单磁通量子电路的超导计算芯片;
2023年10月,由中科南京智能技术研究院自主研发是目前国内规模最大、国际一流的类脑超级计算机服务正式启用,它已实现5亿神经元2500亿突触智能规模,较现有计算系统能效提升10倍以上,核心芯片自主可控。
IBM的成果代表着,这项布局未来的技术离我们又近了一步,而目前一些初创公司逐渐形成方案,开始应用。不难预见,在近几年,这项技术商业化将逐步展开,而彼时研究成果也将照进现实。
相关阅读
RelatedReading





猜你喜欢
Guessyoulike
装配建筑相关公司十强_二季度概念股毛利率榜单出炉!

大众“台柱子”入职长安!官至副总裁,掌管全球设计,变脸计划启动

十大腾讯概念排行榜_相关股票每股收益榜单(第二季度)