2023-11-17 10:37:08 发布人:hao333 阅读( 5920)
最近李开复老师创办的01万物在 OpenAI 开发者大会前一天发布了 大模型 Yi-6B/34B/200K 等一系列模型,本来挺好,结果随着大家的使用,大家纷纷...
最近李开复老师创办的01万物在 OpenAI 开发者大会前一天发布了 大模型 Yi-6B/34B/200K 等一系列模型,本来挺好,结果随着大家的使用,大家纷纷开始吐槽。
不得不说创业难啊,这届群众不好忽悠。以李开复老师的名望,都翻车了。
然后舆论终于在昨天贾扬清的一条朋友圈发布后爆发了。下面是贾扬清的吐槽,虽然没点名,但是说的就是 Yi Model

如果 Yi Model 在发布的时候大方承认自己是基于 Llama 架构,就像 Baichuan ,积极拥抱 Llama 的生态,舆论可能会好一点,但是也不会好很多,只不过是恰好在贾扬清吐槽后集中爆发了。使用 Llama 架构反而是小事,因为现在大家基本上都基于 Llama 在做事情。
原因无非有两点:
模型本身就有虚假宣传的嫌疑,让人觉得是在忽悠钱的。
大家遥远的记忆中的 Start-Copy Lee 又回来了。
翻车现场一:模型效果好到离谱,实际上是做题家
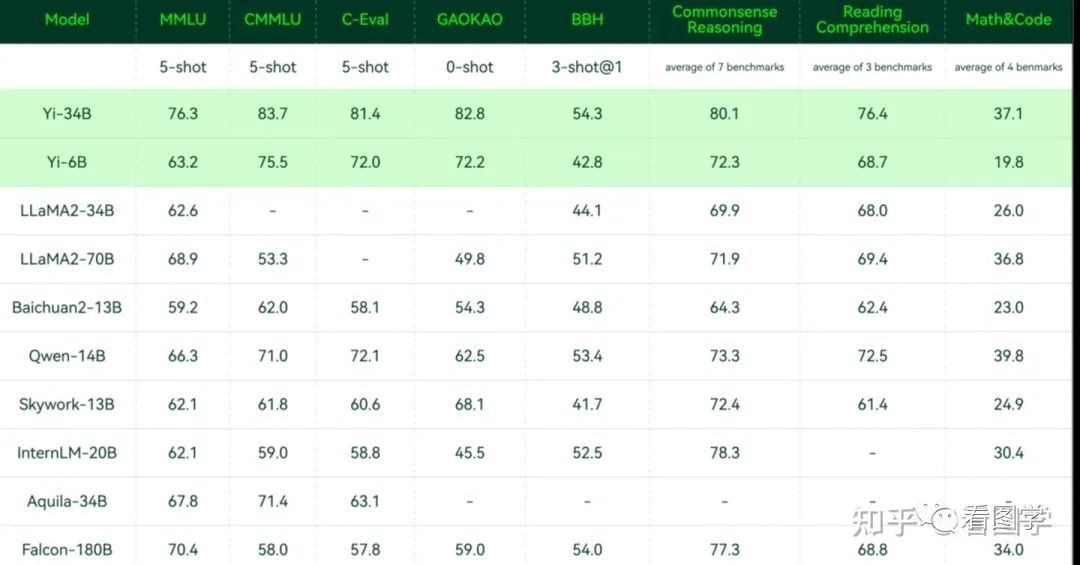
他们给的数据全方位吊打 LLaMA 2-70B,这种贴出来就问你信不信?
之前就写过一篇文章,聊了聊大模型测评国内的一些乱象,感兴趣的可以点击这里:
国内大模型测评现状
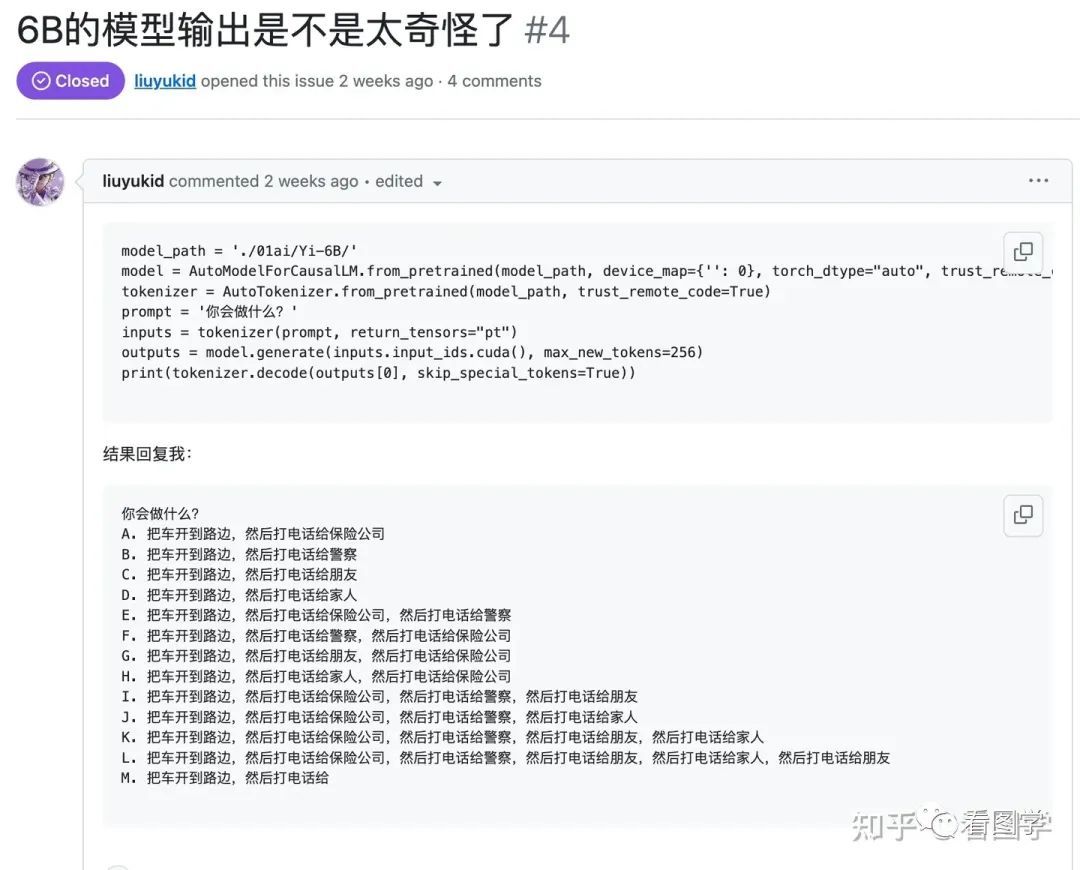
然后呢,有网友就开始测试,发现题目还没出,Yi Model 就开始背答案了。我们知道预训练的 Base Model 其实是一个续写模型,现在直接输出选择题的答案,那很明显就是预训练的时候有大量选择题,所以上面榜单选择题做的好也就不奇怪了。
翻车现场二:长文本支持
最近大模型长度其实卷的也挺厉害,尤其是 Baichuan 和 MoonShot 相继推出长文本后,但是可能是出于商业的目的,长文本的版本并没有支持。这次我看 Yi 放出了 100K 的模型和代码,想着学习一下,结果呢,想象中的 sliding window attention , linear attention 之类的全都没有,然后突然发现 100k 的 modeling_yi.py 和 6b 的一模一样。

这是怎么做到长文本支持的呢?
终于在 RoPE 这里似乎找到了答案

仅仅是将 base 从默认的 10000 扩大了 500 倍来扩展长度?我都很好奇发布这个长文本版本到底贡献了什么。
当然可能是我才疏学浅,还有些细节没注意到。但是长文本的训练代码和短文本的一样,本身就有点问题吧。
关于李开复老师
说实话,首先要感恩李开复老师。李老师对我早期的求学生涯还挺有帮助的,大概十年前了吧,我还逛过李老师创办的学生网,当时印象特别深的是一篇《算法的力量》,可以说是这篇文章让我真正好好学习算法,以至于在后面还参加了百度之星之类的竞赛,在入职百度的时候也算很顺利。
后来李老师创办创新工程,知乎也是李老师投资的,我写这篇可别到时候被夹了啊。这里是公众号,可以多写点。
在 Google 工作的时候呢,搞过 Google 输入法。大家知道早期的 NLP 分词没那么牛逼,尤其是网络上又有大量的新词汇,所以每个输入法都有一个词典,这个是核心竞争壁垒。然后 Google 输入法被人家发现,你的词典用的是我搜狗的啊。。。貌似还有几次抄袭事件,导致别人给起了个外号:李开复 -> 李开始复制 -> Start Copy Lee
再往后呢,李老师开始慢慢变成高晓松,经常以青年导师,精神领袖自居,在林妙可遭受网暴的时候大谈什么言论自由,搞得大家觉得这人是不是精神有点问题。
然后有经常跟一些三观不正的微博达人互动密切,没事就黑政府,大肆宣扬老美制度的优越性。
终于在某一个严打公知的时间点,薛蛮子进监狱。李老师恰好就得了癌症。还在劝大伙,不要熬夜,然后几年后又满血复活了。大家把这一招叫做:癌遁。
插句题外话,薛蛮子发家史也挺精彩的,国内巨贪转移财产后来被薛蛮子截胡人家儿媳妇,钱也拿到了,儿媳妇也拐走了。想听的同学可以关注下面公众号给我留言,人多的话可以再讲讲。
按说李老师年纪也大了,应该好好休息,但是还是想为国内的 AI 贡献一点力量。以李老师的名望,再加上刷榜,再拉一波投资应该问题不大,但是不要再把“搜狗输入法谷歌皮肤”的事情再演绎一遍了。
所以看一个人不要只看他说了什么,还要看他做了什么。“锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦”,谁能想到写这首诗的作者日后成了个大贪官呢?
总之这个事情,让我想起来《潜伏》里面的一段话。

上一篇:跳转的苦,苹果来解?
相关阅读
RelatedReading猜你喜欢
Guessyoulike