“GPT-4只是在压缩数据”,马毅团队造出白盒Transformer,可解释的大模型要来了吗?
2023-11-26 12:34:57 发布人:hao333 阅读( 6851)
机器之心报道编辑:PandaAGI 到底离我们还有多远?在 ChatGPT 引发的新一轮 AI 爆发之后,一部分研究者指出,大语言模型具备通过观察进行因果归纳的...
机器之心报道
编辑:Panda
AGI 到底离我们还有多远?
在 ChatGPT 引发的新一轮 AI 爆发之后,一部分研究者指出,大语言模型具备通过观察进行因果归纳的能力,但缺乏自己主动推理新的因果场景的能力。相比于持乐观预测的观点,这意味着 AGI 仍然是一个复杂而遥远的目标。
一直以来,AI 社区内有一种观点:神经网络的学习过程可能就只是对数据集的压缩。
近日,伯克利和香港大学的马毅教授领导的一个研究团队给出了自己的最新研究结果:包括 GPT-4 在内的当前 AI 系统所做的正是压缩。
通过新提出的深度网络架构 CRATE,他们通过数学方式验证了这一点。
而更值得注意的是,CRATE 是一种白盒 Transformer,其不仅能在几乎所有任务上与黑盒 Transformer 相媲美,而且还具备非常出色的可解释性。
基于此,马毅教授还在 Twitter 上分享了一个有趣的见解:既然当前的 AI 只是在压缩数据,那么就只能学习到数据中的相关性 / 分布,所以就并不真正具备因果或逻辑推理或抽象思考能力。因此,当今的 AI 还算不是 AGI,即便近年来在处理和建模大量高维和多模态数据方面,深度学习在实验中取得了巨大的成功。
但很大程度上,这种成功可以归功于深度网络能有效学习数据分布中可压缩的低维结构,并将该分布转换为简约的表征。这样的表征可用于帮助许多下游任务,比如视觉、分类、识别和分割、生成。
表征学习是通过压缩式编码和解码实现的
为了更形式化地表述这些实践背后的共同问题,我们可以将给定数据集的样本看作是高维空间 ℝ^D 中的随机向量 x。
通常来说,x 的分布具有比所在空间低得多的内在维度。一般来说,学习某个表征通常是指学习一个连续的映射关系,如 f ,其可将 x 变换成另一个空间 ℝ^d中的所谓特征向量 z。人们希望通过这样一种映射:
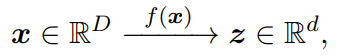
能以一种紧凑且结构化的方式找到 x 的低维内在结构并使用 z 来表示它,然后借此帮助分类或生成等后续任务。特征 z 可被视为原始数据 x 的紧凑编码,因此映射 f 也称为编码器。
这样一来,表征学习的基础问题便成了:
为了衡量表征的优劣,有什么有数学原理保证且有效的衡量方法?
从概念上讲,表征 z 的质量取决于它为后续任务找到 x 的最相关和充分信息的程度以及它表示该信息的效率。
长期以来,人们都相信:所学习到的特征的「充分性」和「优良度」应当根据具体任务而定义。举个例子,在分类问题中,z 只需足以用于预测类别标签 y 即可。
为了理解深度学习或深度网络在这种类型的表征学习中的作用,Tishby and Zaslavsky 在论文《Deep learning and the information bottleneck principle》中提出了信息瓶颈框架,其提出:衡量特征优良度的一种方法是最大化 z 和 y 之间的互信息,同时最小化 z 和 x 之间的互信息。
然而,近年来普遍通行的做法是首先预训练一个大型深度神经网络来学习与任务无关的表征。之后再针对多个具体任务对学习到的表征进行微调。研究表明这种方法能有效且高效地处理许多不同数据模态的实践任务。
请注意,这里的表征学习与针对特定任务的表征学习非常不同。对于针对特定任务的表征学习,z 只需能预测出特定的 y 就足够了。在与任务无关的情况下,所学到的表征 z 需要编码几乎所有与数据 x 的分布有关的关键信息。也就是说,所学习到的表征 z 不仅是 x 的内在结构的更紧凑和结构化表征,而且还能以一定的可信度恢复出 x。
因此,在与任务无关的情况下,人们自然会问:对于学习到的表征,一个衡量其优良度的有原理保证的度量应该是什么?
研究者认为,一种有效方法是:为了验证表征 z 是否已经编码了有关 x 的足够信息,可以看通过如下映射能从 z 多好地恢复出 x:

由于编码器 f 通常是有损压缩,因此我们不应期望其逆映射能精确地恢复出 x,而是会恢复出一个近似
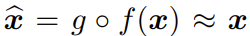
我们通常会寻找最优的编码和解码映射,使得解码得到的
与 x 最接近 —— 无论是样本方面还是在宽松的分布意义上。
研究者将上述这个过程称为压缩式编码和解码或压缩式自动编码。这一思想与自动编码器的原始目标高度兼容,而自动编码器则可被看作是经典的主成分分析泛化用于 x 有线性的低维结构的情况。
过去十一年来,大量实验已经清楚地表明:深度网络能够非常有效地建模非线性编码和解码映射。
深度学习的几乎所有应用都依赖于实现这样的编码或解码方案,其方式是部分或完全地学习 f 或 g,当然它们可以分开或一起学习。
尽管从概念上讲,解码器 g 应该是编码器 f 的「逆」映射,但在实践中,我们一直不清楚编码器和解码器的架构有何关联。在许多案例中,解码器的架构设计与编码器的关联不大,通常是通过实验测试和消融实验选取的。
可以想见,一个优秀的表征学习理论框架应能清楚地揭示编码器和解码器架构之间的关系。而这正是这项研究希望达成的目标。
研究者总结了之前提出的相关方法,并将其分成了以下几种情况:
通过压缩打开现代深度网络的黑盒。
Transformer 模型和压缩。
去噪扩散模型和压缩。
促进低维度的度量:稀疏性和率下降。
展开优化:一个用于网络解释和设计的统一范式。
详情参看原论文。
这项研究的目标和贡献
他们搭建了理论和实践之间的桥梁。为此,这项研究提出了一个更加完整和统一的框架。
一方面,这个新框架能对基于深度网络的许多看似不同的方法提供统一的理解,包括压缩式编码 / 解码、率下降和去噪扩散。
另一方面,该框架可以指导研究者推导或设计深度网络架构,并且这些架构不仅在数学上是完全可解释的,而且在大规模现实世界图像或文本数据集上的几乎所有学习任务上都能获得颇具竞争力的性能。
基于以上观察,他们提出了一个白盒深度网络理论。更具体而言,他们为学习紧凑和结构化的表征提出了一个统一的目标,也就是一种有原理保证的优良度度量。对于学习到的表征,该目标旨在既优化其在编码率下降方面的内在复杂性,也优化其在稀疏性方面的外在复杂性。他们将该目标称为稀疏率下降。图 3 给出了这一目标背后的直观思想。
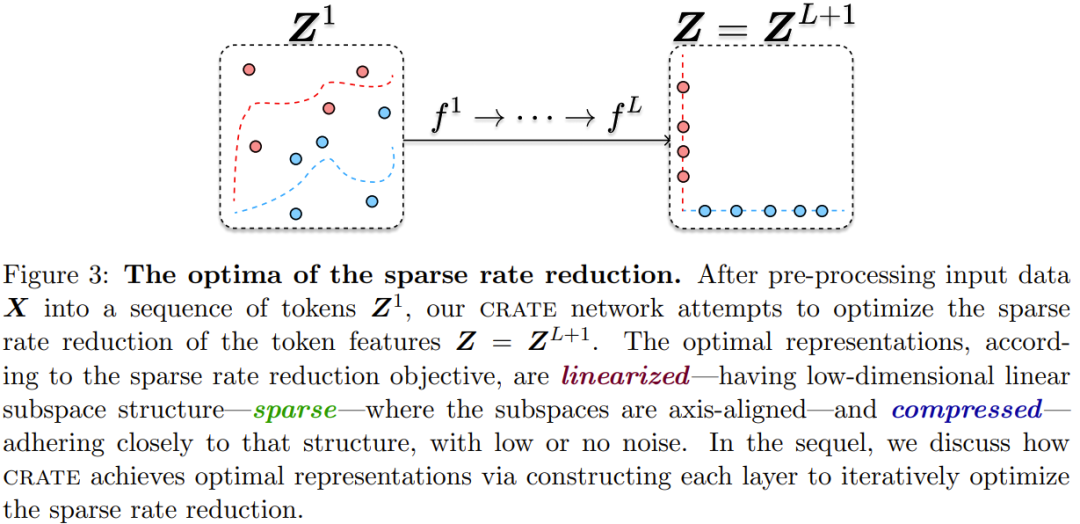
为了优化这个目标,他们提出可以学习一个增量映射序列,其能模拟展开目标函数的某些类似梯度下降的迭代优化方案。这自然地会得到一个类似 Transformer 的深度网络架构,并且它完全是一个「白盒」—— 其优化目标、网络算子和学习到的表征在数学上是完全可解释的。
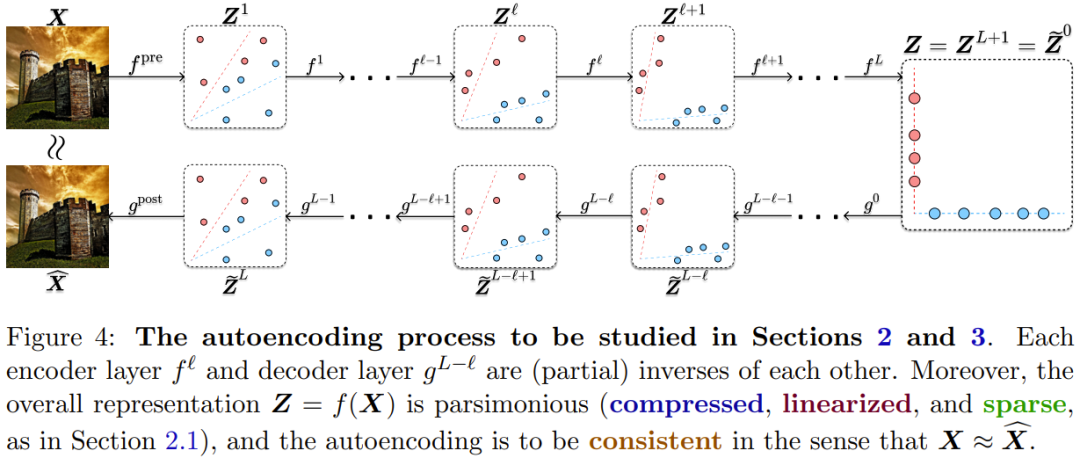
他们将这个白盒深度架构命名为 CRATE 或 CRATE-Transformer,这是 Coding-RATE transformer 的缩写。他们还通过数学方式证明这些增量映射在分布的意义上是可逆的,并且它们的逆映射本质上由同一类数学算子构成。
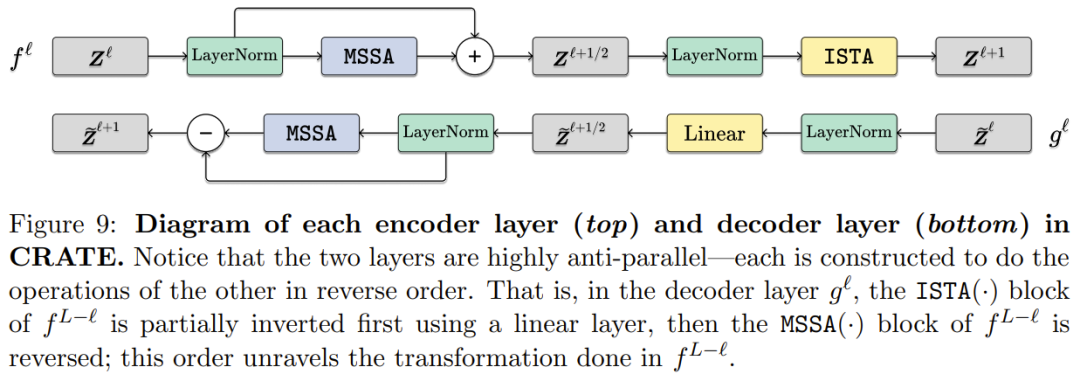
因此,可以将几乎完全一样的 CRATE 架构用于编码器、解码器或自动编码器。如图 4 给出了一个自动编码过程,其中每个编码层 f^𝓁 和解码层 g^{L-𝓁} 是可逆的。
下图给出了 CRATE 白盒深度网络设计的「主循环」。
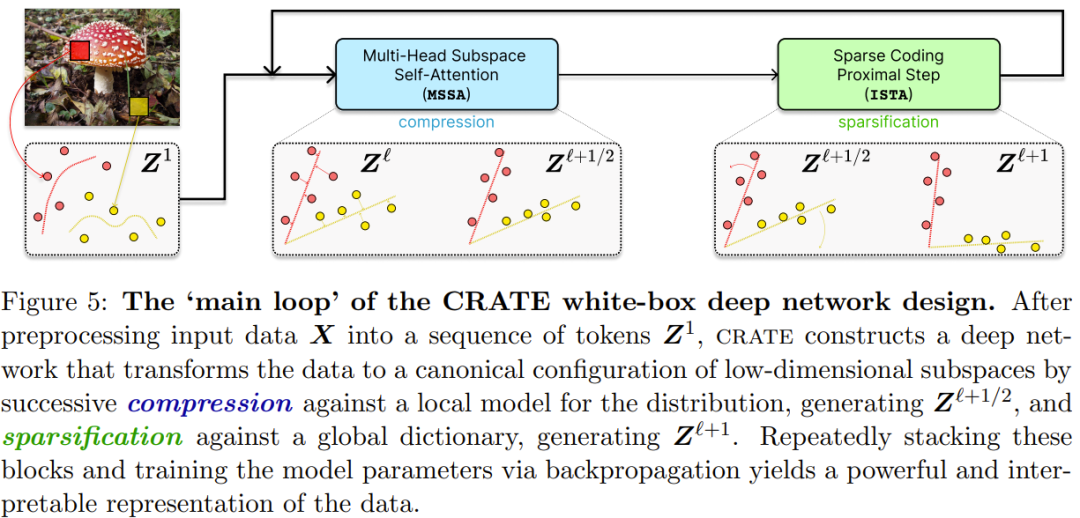
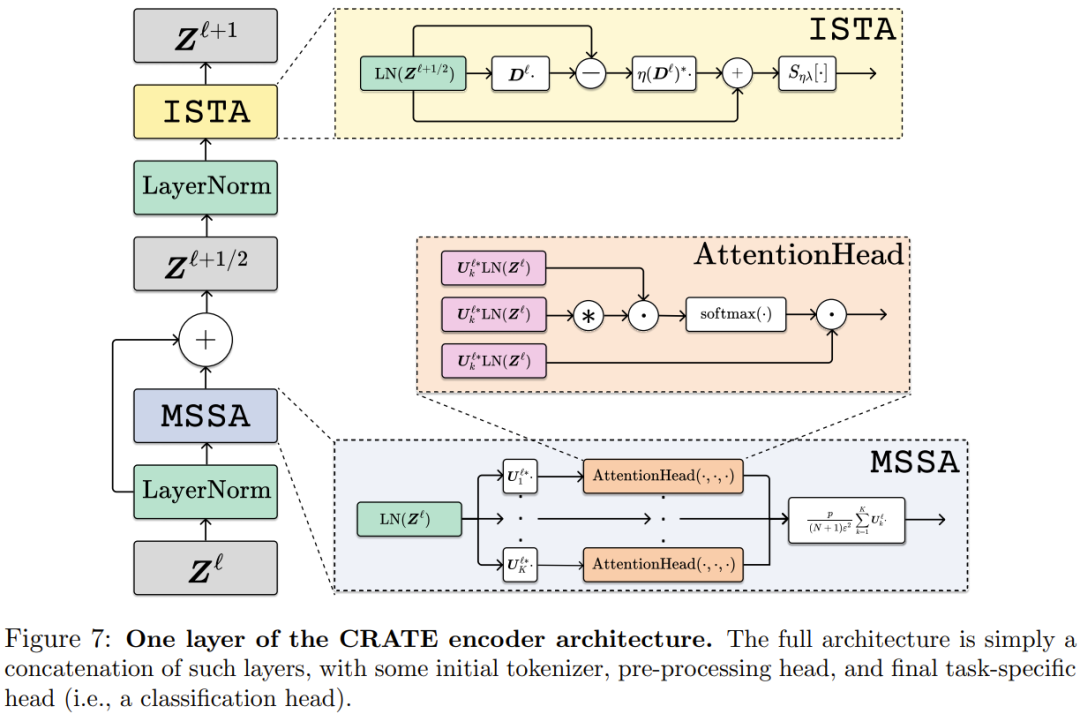
在将输入数据 X 预处理为一系列 token Z^1 后,CRATE 会构建一个深度网络,其可将数据转换为低维子空间的规范配置,其做法是针对分布的局部模型进行连续压缩生成 Z^{ℓ+1/2},以及针对一个全局词典执行稀疏化,得到 Z^{ℓ+1}。通过重复堆叠这些模块并使用反向传播训练模型参数,可以得到强大且可解释的数据表征。
下面则给出了 CRATE 编码器架构的一层。其完整架构就是将这些层串连起来,再加上一些初始 token 化器、预处理头和最后的针对具体任务的头。
下图对比了编码器层和解码器层,可以看到两者是部分可逆的。
更多理论和数学描述请参阅原论文。
实验评估
为了证明这个框架确实能将理论和实践串连起来,他们在图像和文本数据上执行了广泛的实验,在传统 Transformer 擅长的多种学习任务和设置上评估了 CRATE 模型的实际性能。
下表给出了不同大小的 CRATE 在不同数据集上的 Top-1 准确度。
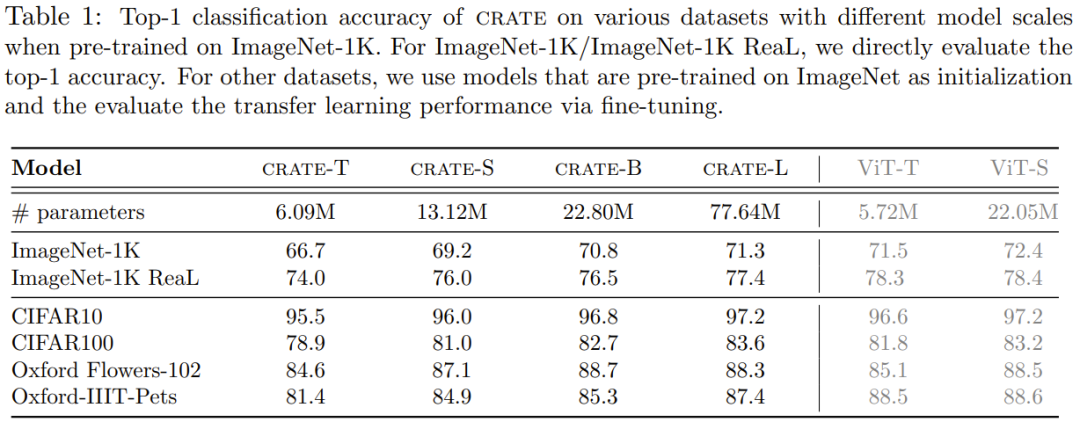
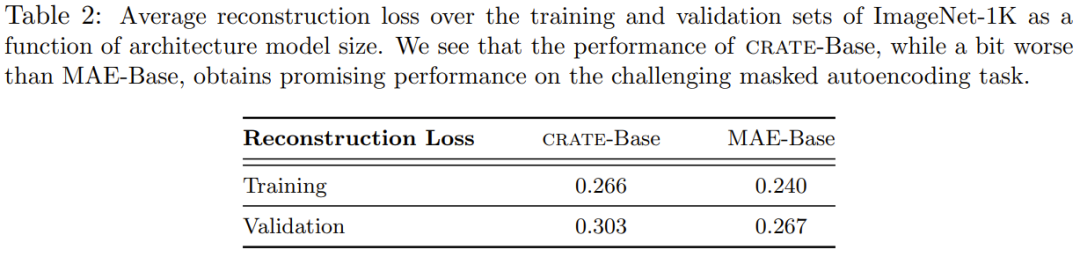
表 2 给出了 CRATE-Base 模型与 MAE-Base 模型在训练和验证集上的平均重建损失。
令人惊讶的是,尽管其概念和结构很简单,但 CRATE 在所有任务和设置上都足以与黑盒版的对应方法媲美,这些任务包括通过监督学习进行图像分类、图像和语言的无监督掩码补全、图像数据的自监督特征学习、通过下一词预测的语言建模。
此外,CRATE 模型在实践上还有其它优势,每一层和网络算子都有统计和几何意义、学习到的模型的可解释性显著优于黑盒模型、其特征具有语义含义。
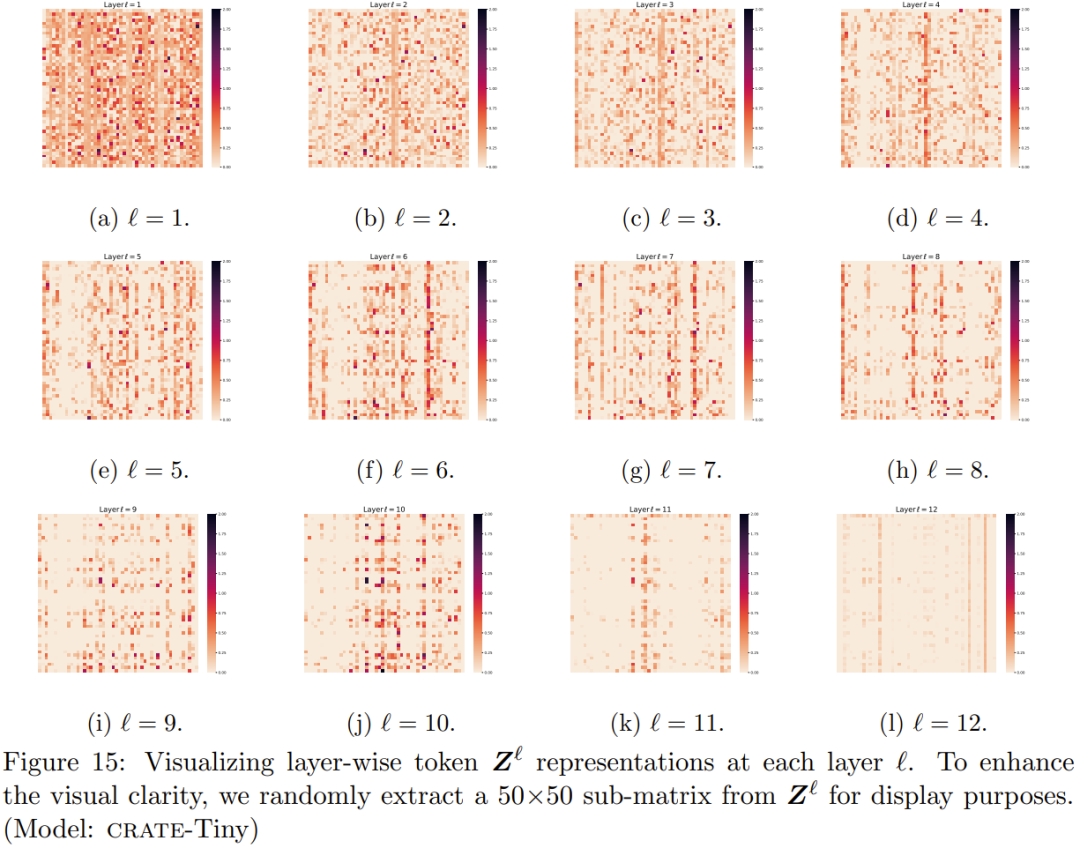
下图便给出了在每层 ℓ 的逐层 token Z^ℓ 表征的可视化。
下图展示了来自监督式 CRATE 的自注意力图。

注意由于资源限制,他们在实验中没有刻意追求当前最佳,因为那需要大量工程开发或微调。
尽管如此,他们表示这些实验已经令人信服地验证了新提出的白盒深度网络 CRATE 模型是普遍有效的,并为进一步的工程开发和改进奠定了坚实的基础。
相关阅读
RelatedReading


猜你喜欢
Guessyoulike
主板光刻机公司(主板光刻机股票名单2023)

燃气概念股有哪些(主板燃气股票是哪些)

2023年粗醇利好什么股票?A股粗醇概念股有哪些?