谷歌深夜放复仇杀器Gemini,最强原生多模态史诗级碾压GPT-4!语言理解首超人类
2023-12-07 14:27:45 发布人:hao333 阅读( 2313)
【新智元导读】传说中的Gemini,终于在今天深夜上线了!「原生多模态」架构,是谷歌的史诗级创举,Gemini也如愿在多个领域超越了GPT-4。这场仗,谷歌必不...

【新智元导读】传说中的Gemini,终于在今天深夜上线了!「原生多模态」架构,是谷歌的史诗级创举,Gemini也如愿在多个领域超越了GPT-4。这场仗,谷歌必不能输。
谷歌的复仇大杀器Gemini,深夜忽然上线!
被ChatGPT压着打了整整一年,谷歌选择在12月的这一天,展开最强反击战。
多模态Gemini,迄今规模最大、能力最强的谷歌大模型,在文本、视频、语音等多个领域超越了GPT-4,是真正的一雪前耻。

人类有五种感官,我们所建造的世界、所消费的媒体,都是以这样的方式所呈现。
而Gemini的出现,就是迈向真正通用的AI模型的第一步!

Gemini的诞生,代表着AI模型的巨大飞跃,谷歌所有的产品,都将随之改头换面。
塞进多模态模型的搜索引擎、广告产品、Chrome浏览器……这,就是谷歌给我们的未来。
多模态的史诗级创新
以前,多模态大模型就是将纯文本、纯视觉和纯音频模型拼接在一起,就像OpenAI的GPT-4、DALL·E和Whisper那样。然而,这并不是最优解。
相比之下,在设计之初,多模态就是Gemini计划的一部分。
从一开始,Gemini就在不同模态上进行了训练。随后,研究人员又用额外的多模态数据进行了微调,进一步提升了模型的有效性。最终,实现了「无缝」地理解和推理各种模态的输入内容。
从结果上来看,Gemini的性能要远远优于现有的多模态模型,而且它的功能几乎在每个领域都是SOTA级别的。
而这个最大、最有能力的模型,也意味着Gemini可以用和人类一样的方式理解我们周围的世界,并且吸收任何类型的输入和输出——无论是文字,还是代码、音频、图像、视频。

Gemini猜对了纸团在最左边的杯子里
Google DeepMind首席执行官兼联合创始人Demis Hassabis表示,谷歌一直对非常通用的系统感兴趣。
而这里最关键的,就是如何混合所有这些模式,如何从任意数量的输入和感官中收集尽可能多的数据,然后给出同样多样化的响应。
DeepMind和谷歌大脑合并后,果然拿出了真东西。
之所以命名为Gemini,就是因为谷歌两大AI实验室的合体,另外也一个解释是参考了美国宇航局的Gemini项目,后者为阿波罗登月计划铺平了道路。
首次超越人类,大幅碾压GPT-4
虽然没有正式公布,但根据内部消息,Gemini有万亿参数,训练所用的算力甚至达到GPT-4的五倍。
既然是被拿来硬刚GPT-4的模型,Gemini当然少不了经历最严格的测试。
谷歌在多种任务上评估了两种模型的性能,惊喜地发现:从自然图像、音频、视频理解到数学推理,Gemini Ultra在32个常用的学术基准的30个上,已经超越GPT-4!
而在MMLU测试中,Gemini Ultra以90.0%的高分,首次超过了人类专家。
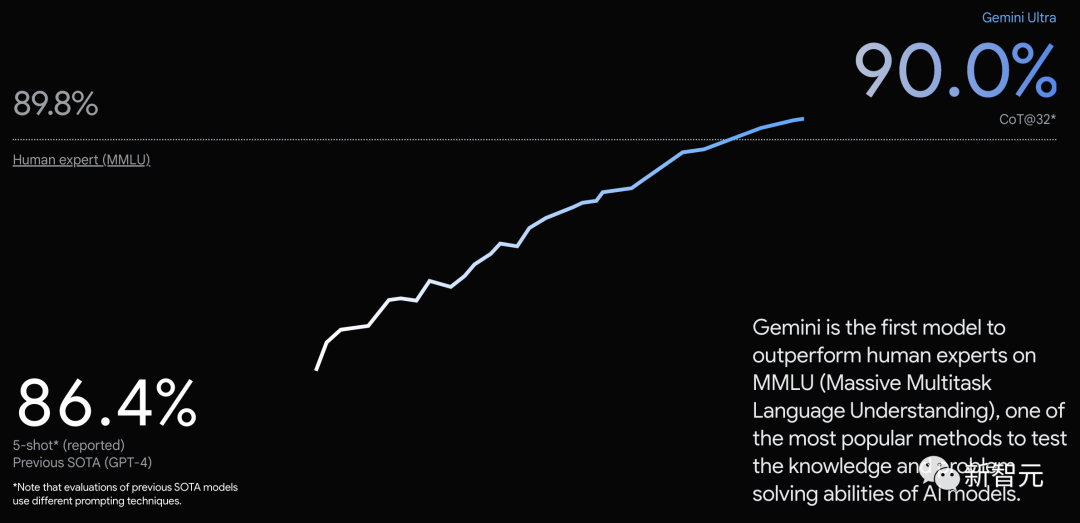
Gemini是第一个在MMLU上超越人类专家的模型
MMLU测试包括57个学科,如数学、物理、历史、法律、医学和伦理,旨在考察世界知识和解决问题的能力。
在这50多个不同学科领域中的每一个中,Gemini都和这些领域最好的专家一样好。
谷歌为MMLU设定的新基准,让Gemini在回答复杂问题前,能够更仔细地发挥推理能力,相比于仅依赖于直觉反应,这种方法带来了显著提升。
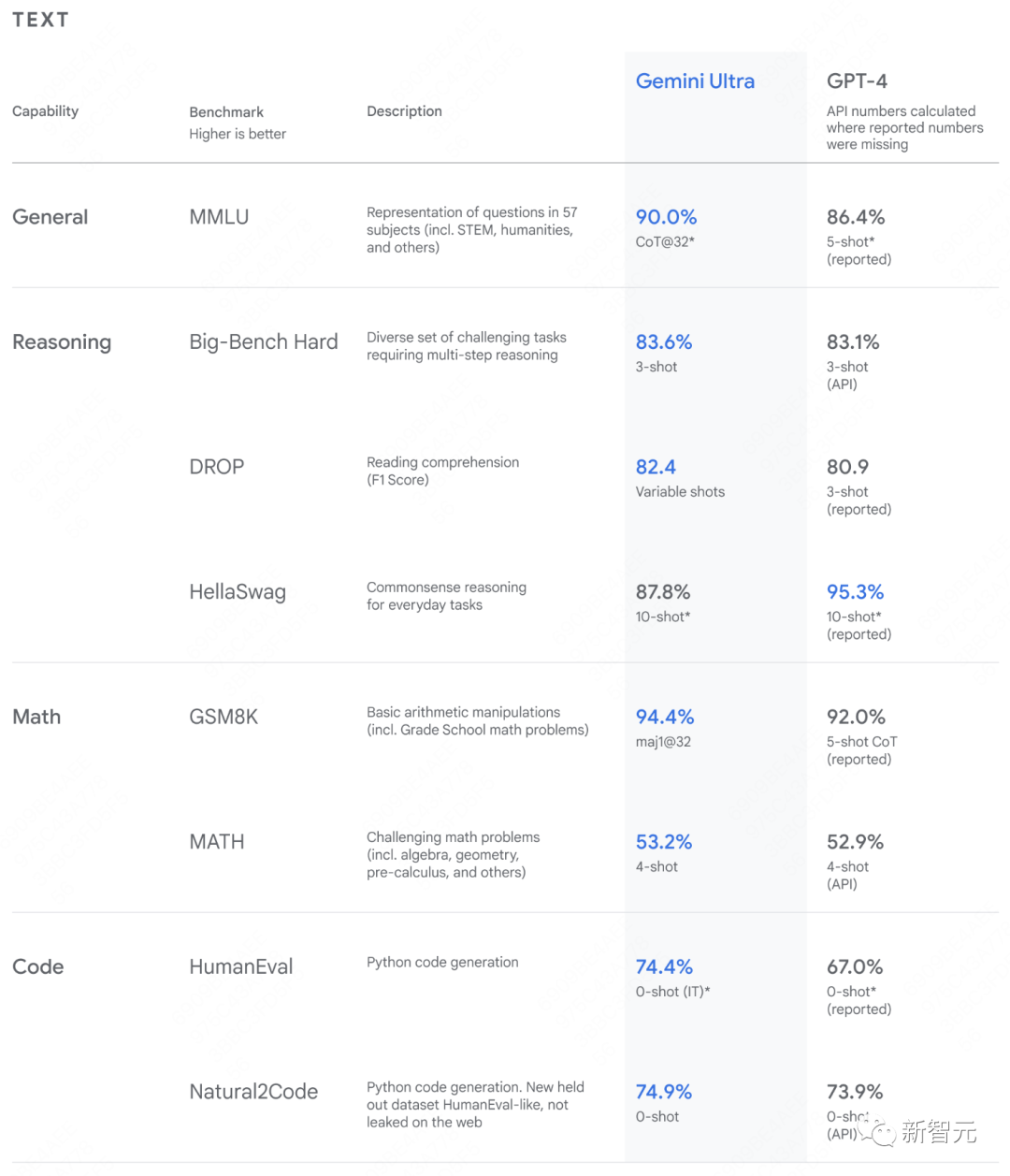
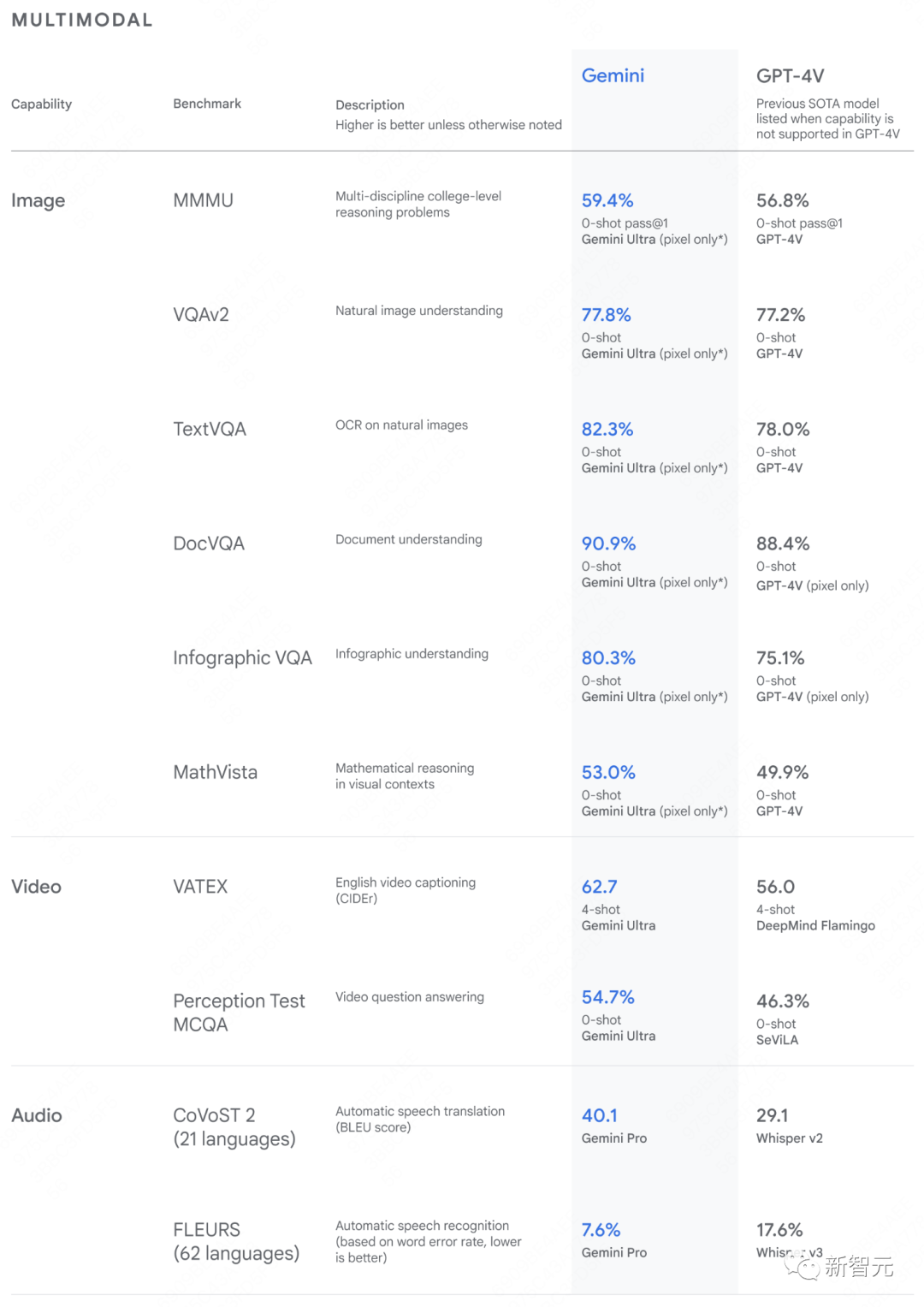
在新的MMMU基准测试中,Gemini Ultra也取得了59.4%的高分,这一测试包括了跨越不同领域的多模态任务,这些任务需要深入的推理过程。
图像基准测试中,Gemini Ultra的表现也超过了之前的领先模型,而且,这一成就是在没有OCR系统帮助的情况下实现的!
种种测试表明,Gemini在多模态处理上表现出了强大的能力,并且在更复杂的推理上也有着极大潜力。
详情可参阅Gemini技术报告:

报告地址:https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
中杯、大杯、超大杯!
Gemini Ultra是谷歌迄今为止创建的最强大LLM最大,能够完成高度复杂的任务,主要面向数据中心和企业级应用。
Gemini Pro是性能最好的模型,用于广泛的任务。它会为许多谷歌的AI服务提供动力,并且从今天起,成为Bard的支柱。
Gemini Nano是最高效的模型,用于设备端任务,可以在安卓设备上本地和离线运行,Pixel 8 Pro的用户就能马上体验到。其中,Nano-1的参数为1.8B,Nano-2为3.25B。

Gemini最基本的模型能做到文本输入和文本输出,但像Gemini Ultra这样更强大的模型,则可以同时处理图像、视频和音频。
不仅如此,Gemini甚至还能学会做动作和触摸这种更像机器人的功能!
以后,Gemini会获得更多的感官,变得更加有意识,更加准确。
虽然幻觉问题仍然不可避免,但模型知道的越多,性能就会越好。
文本、图像、音频精准理解
Gemini 1.0经过训练,可以同时识别和理解文本、图像、音频等各种形式的输入内容,因此它也能更好地理解细微的信息,回答与复杂主题相关的各类问题。
比如,用户先是上传了一段非英语的音频,然后又录了一段英语的音频来提问。
要知道,一般设计音频的归纳,都是用文字输入prompt。而Gemini却可以同时处理两段不同语言的音频,精准输出所需要的摘要内容。
相关阅读
RelatedReading



猜你喜欢
Guessyoulike
绑架男神电影免费完整版观看(绑架男神电影免费完整版观看/葛乃荣/120分钟免费剧情观看)

2023年肾透析概念相关上市公司一览(12月7日)
2023年版!华为智界概念上市公司名单合集(12月7日)