谷歌造出了比人还牛的AI大模型?
2023-12-07 22:51:17 发布人:hao333 阅读( 1667)
今天凌晨,谷歌发布了全新的大模型——双子星,号称在多方面超过 GPT4.0 ,起初,我是不在意的,毕竟几乎每个大模型都曾声称“超过”GPT4.0,但用起来,一个...
今天凌晨,谷歌发布了全新的大模型——双子星,号称在多方面超过 GPT4.0 ,起初,我是不在意的,毕竟几乎每个大模型都曾声称“超过”GPT4.0,但用起来,一个能打的都没有。
但看完Gemini的演示,人直接傻掉了,这种震撼不亚于第一次看到ChatGPT和人类交流,黑猩猩第一次把骨头扔上天,哆啦A梦给大雄掏出任意门。
演示刚开始,测试人员就和Gemini玩起了“街头杂耍”,将一个纸球放进三个杯子里,然后不停的变换,最终,让Gemini猜纸球在哪个杯子里,不出意外, 它猜对了 。

01
AI第一次的真·多模态
在这过程中,Gemini仅靠视频画面,不仅识别出游戏,还把自己代入了参与者的角色,并且还猜对了答案。这种 多模态 的输入能力,在之前是从来没有过的!
当然,这还不算完,演示人员还展示了一个鸭子从简笔画到上色的过程,其中的每一步,Gemini不仅准确识别,甚至还说出“蓝色鸭子不常见,建议使用黄色等常见颜色”。整个过程,都在 下面的视频中展示 出来了 ,大家点开看看,保证大受震撼。
在人类把蓝色橡皮鸭子拿出来后,Gemini也做出幽默的反应,并且识别出它的材质和作用,最后,Gemini甚至还纠正了测试者普通话“鸭子”的 发音 ,这一波,可谓是把Gemini多模态能力的秀到爆炸。
当然,不止如此,如果各位老爷继续看完这个视频,会发现像 猜拳 , 识别物品 , 识别电影镜头 ,这些对于AI来讲,都已经不是难题了。

那么,Gemini的这种 多模态能力 是为何如此突出的呢?为什么像GPT4.0这样的大模型做不到如此“丝滑”?
我们先来看看目前的AI是如何实现多模态的。在训练 文本模型 的时候,只灌输书籍,文章类的文本数据,训练 图像模型 的时候,训练数据就变为了各式各样的图片,视频,音频等模型,也是如此。
因此,不同模态的模型之间是有一定 隔阂 的,拿B站的视频AI总结来说,声音模型先把视频的声音转成文字,然后再转给处理文字的模型,最终成为了文字版的总结。
换句话讲,目前的多模态模型,并不能像人一样去理解视频。但Gemini完全不一样,它是 原生的多模态模型 。从训练初始,Gemini一直被投喂的数据, 就是文本+语音+图片+视频 。也就是说,Gemini可以像人类一样理解看到的内容,数据不需要在多个模型之间来回流转,一个模型就搞定了一切。
根据演示,Gemini可以很好的将各种模态下的信息,整合到一起进行推理,除了前面视频中额演示外,谷歌还放出很多演示视频,再说两个令人深刻的吧。
第一个是人类要求Gemini根据这个树的图片,生成无损放大的矢量图,Gemini照猫画虎做出来了。紧接着的要求就 变态 了,要求用HTMl和JavaScript编程语言,生成这个树。结果还真被Gemini搞出来了。从这两点可以看出,Gemini的多模态输出能力也很强悍。

第二个就是关于解答数学和物理题目的。放几张学生 潦草 的作业上去,Gemini都可以判断出答案的正确与否,并且根据错误的地方,给出正确的推导过程,看来,数学和物理都是手拿把掐。
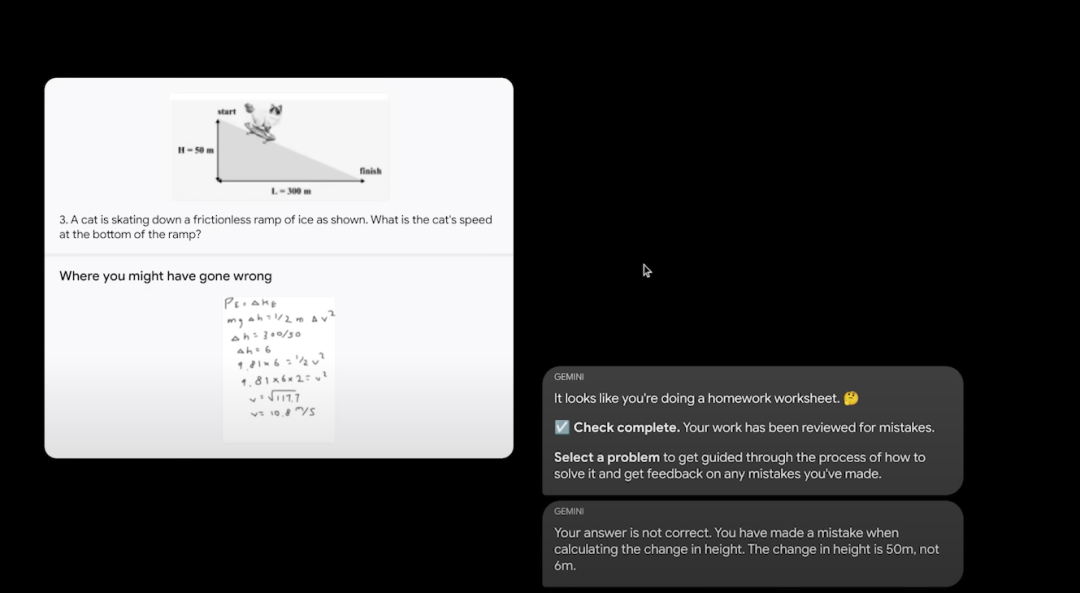
02
Gemini性能超越GPT4.0?
之所以在数学和物理上有这么强的能力,和Gemini超强的性能分不开。除了多模态的识别,Gemini在常识,推理上也创造了很多记录,从结果图标上看, 它几乎超越了目前最强模型GPT4.0 。
根据谷歌的技术文档显示,Gemini在32个AI模型评测中都拔得了头筹。更令人意外的是,它还达成了MMLU中首次超过人类专家的成就,成为 第一个 完成此壮举的AI。
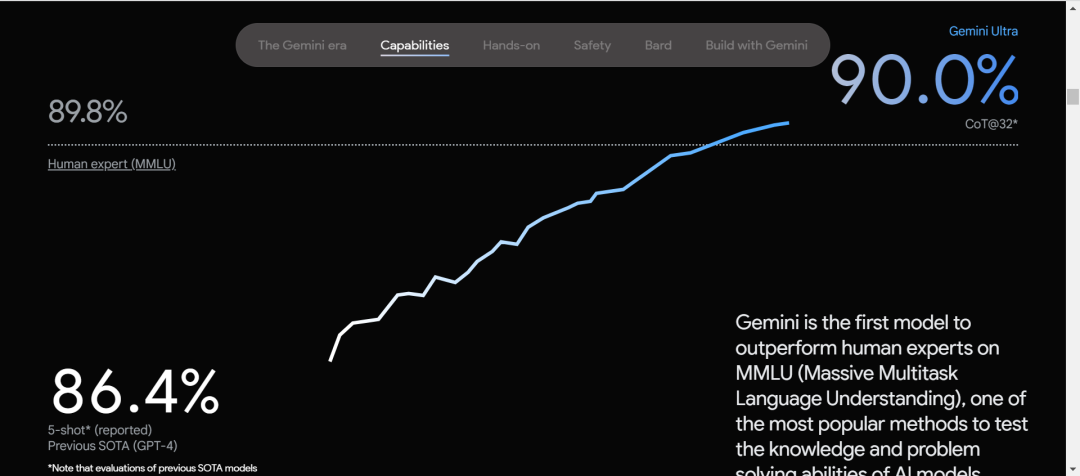
MMLU全称是测量大模型多任务下的语言理解能力。读起来挺拗口,其实很好理解,这个就像对于大模型的 中考 ,里面包含了基础数学,历史,法律等共57个方面的题目,难度从高中到大学不等。
在MMLU出来后,人类各方面的专家做过测试,平均下来正确率为 89.8% ,所以MMLU的作者就把这个89.8%作为一个标准,谁家AI能超过它,那你就比人类还牛了。
其中的题目是啥样的呢?我们把这些题目下载过来,简单看了看,发现含金量还是有的,比如在“会计”项目中,题目大多是这样的:
你花98,000美元买了一辆豪华轿车,并计划以每小时245美元的价格出租用于婚礼、典礼和派对。如果你估计这辆车平均每天被租用2小时,每天的成本约为50美元,那么如果你全年无休地工作,即包括任何节日和周末在内,你投资的预估年收益是多少?
不知道各位会不会算,反正办公室的同事们还是费了点功夫的。法律部分的题目如下:
一地方法律规定:"任何人在知道或应该知道自己正在被警察逮捕时,有责任不使用武力或任何武器抵抗逮捕"。违反该法律规定将受到罚款和/或监禁。一天早晨,该地方 发生了一起银行抢劫案。当天下午,一名警官逮捕了一名他认为涉及犯罪的嫌疑人。然而,警官和嫌疑人对接下来发生的事情的描述不一致。据警官称,嫌疑人在被捕后抵抗逮捕,并用拳头打了警官的嘴。警官一时愣住后,拔出警棍并用其击打嫌疑人的头部。另一方面,嫌疑人声称,在他被逮捕后,他辱骂了警察,随后警官开始用警棍打他。为了避免再次被打,嫌疑人用拳头击倒了警官。嫌疑人被指控为袭击罪。嫌疑人应该被判定为:
A:如果逮捕是非法的,没有合理的理由,并且陪审团相信嫌疑人的陈述,那么嫌疑人应被判定为无罪
B:如果逮捕是合法的,并且陪审团相信嫌疑人的陈述,那么嫌疑人应被判定为无罪
C:如果逮捕是合法的,无论陪审团相信哪一方的陈述,嫌疑人应被判定为有罪
D:如果逮捕是合法的,并且陪审团相信嫌疑人的陈述,那么嫌疑人应被判定为无罪
说实话,看完题干,不少同事都已经放弃了。MMLU中共有15908道题目,这里就随便放出上面两道给大家看看强度。Gemini在这个测试中,准确率达到了90.04%,略微超过了人类专家,也超过了准确率为 86.4% 的GPT4.0。
MMLU是2年前左右创建的,当时主要测试的还都是纯文本的理解能力,所以在这个测试中,并没有多模态的测试。因此对目前的大模型们来说,这个难度只能算是中考。
MMMU才是真正的 高考 ,在这个测试中,不仅难度全面升级到大学水平。还加入了许多图片和图标, 考察模型的多模态能力 。这里也给大家放出一个,感受下:

题干 翻译如下 :图1中的数据是通过在高速公路上进行延时摄影获得的。使用回归分析将这些数据拟合到格林希尔兹模型,并确定阻塞密度。
说实话,虽然翻译过来每一个字都明白,但是合在一起,没有相关的专业知识背景,基本上不明白它的题干是什么。现在,再给大家感受下相对简单的题目:

两枚硬币在转盘上旋转,硬币B离轴心的距离是硬币A的两倍:
A:A的速度是B的两倍
B:A的速度和B相等
C:A的速度是B的一半
这个题目应该还算简单,正确答案是C,如果你答错了,没事,GPT-4V答对了。前面的那道题正确答案是B,如果你答错了,没事,GPT-4V也答错了。
在MMMU的测试中,地表最强模型GPT-4V的正确率为 56.8% ,Gemini为 59.4% ,以微小的优势,成为了目前MMMU测试中,正确率最高的模型。
当然,除了MMLU和MMMU,Gemini在像数学,推理,语音识别,图像识别,视频识别等测试中也都超过了GPT4。
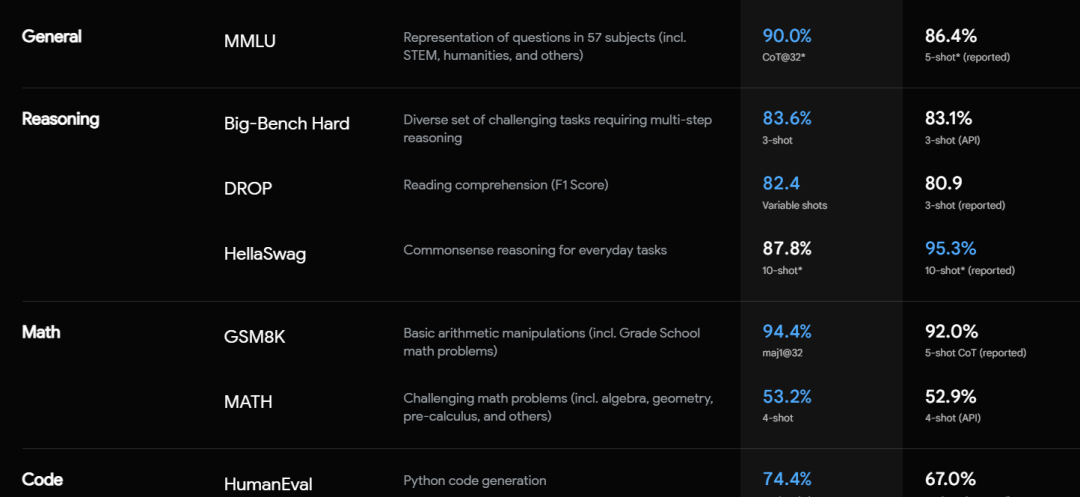
但是!谷歌的这些成绩,是在使用了 思维链 的情况下,在 32次 测试中选择一次最高分取得的,而GPT4则是在正常的情况下测试了 5次 ,取得最高分。
思维链就像旁边有一位指导老师一样,帮助进行一些解释。比如你不认识上面题干中的东西,老师就会做一些辅导:你可以把硬币理解成一个物体,它和题目并没有直接关系;不理解速度的含义,就会告诉AI,速度就是一个物体移动的快慢。
所以Gemini在MMLU的成绩多少有些不光彩,不过MMMU的测试,两者都是在条件几乎相同的情况下完成的。
总而言之,从性能测试上看,这次Gemini能不能超越GPT4不好说,但平起平坐应该问题不大。不过最有意思的是谷歌在训练Gemini所用的硬件——谷歌自己研究的T PU芯片,而不是老黄的GPU。
03
谷歌:AI全链路自产自销
在介绍完Gemini后,最新一代的谷歌TPU计算系统——Cloud TPU v5p也登场了。TPU是谷歌用来专门计算AI的芯片,它对于张量计算有着优化,并且针对自己的TensonFlow框架有着非常好的支持。

换成人话讲,就是谷歌自己发明了一种芯片,对于自己的AI开发框架有着特殊的调优,在训练Gemini的过程中,全部使用的都是TPU,老黄的GPU靠边去。
看来,目前谷歌在AI训练上,已经形成了自产自销的的链条,相比OpenAI的只做软件,谷歌这一步,算是了。
这次Gemini共发布了 三个版本 ,上面的测试都是在超大杯——Gemini Ultra版本中测得的,Ultra也是Gemini的完全体,用来应付一些极其复杂的任务,目前只针对一些机构和专业人员开放。预计明年年初,会对所有的机构和专业人员开放。
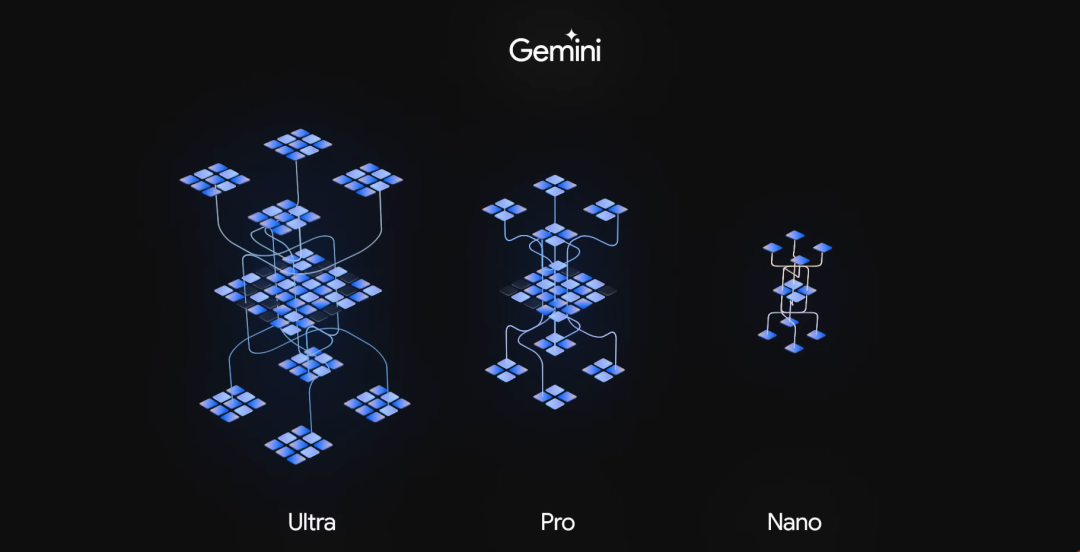
Pro版本针对的就是普通的用户了,它性能和Ultra版相比还差点,根据官方文档来看,Pro版本的水平略强于GPT3.5。目前它已经部署在自家的聊天AI——Bard上,但是明年年初才开放多模态的能力,并且同时还将开放采用Ultra版本的Bard Advanced,到时候大家就可以拍视频问AI了。
Nano则是运行手机等移动设备上的端侧AI,谷歌宣布最先运行Gemini Nano是自家的Pixel 8 Pro手机。
AGI还有多远
前两天是ChatGPT问世一周年,不少同事都在朋友圈晒了截图。在这一年时间中,AI进步的不说肉眼可见,但也绝对是神速了。
从GPT3到3.5再到4.0,对于纯文本的理解上,AI目前已经完全可用,甚至在很多方面超越人类了。而今天谷歌Gemini的发布,昭示了AI下一步——多模态,也在向我们无限靠近。
并且这也预告着,明年大模型互卷的方向将从理解和推理能力转到多模态中,预计明年这个时候,我们已经可以通过声音,图片和视频和AI交流了。
拉回到现实中,几年前,谷歌利用AlphaGo击败了李世石,今天它带着Gemini杀了回来,看来明年的AI大战一定会非常精彩。
像贾维斯一样的通用人工智能,是所有AI参与者追求的目标,现在它已经可以看,听,说了。那么离AI帮助人类做出决策还有多远呢?到时候,我一定要体验下真正的AI女友是什么样的。我们一起期待吧。
酷玩实验室整理编辑
相关阅读
RelatedReading



猜你喜欢
Guessyoulike
房地产业调整,对地方财政收入影响有多大

第66号当铺电视剧全集免费播放(第66号当铺第6集完结,每集45分钟剧情免费看)

深圳“0.5成首付”刷屏!三成首付开发商白送两成半?最新回应来了